索引模型
安全数据湖 透明化管理一个或多个索引集以优化搜索分析操作,实现高速与低资源消耗
为支持管理具有不同 映射关系 , 分析器 ,以及 复制设置 , 安全数据湖 使用索引集作为这些设置的综合抽象。关于创建索引默认配置模板的信息,请参阅索引集模板。
索引集
每个索引集包含 安全数据湖 创建、管理和填充搜索后端索引所需的设置,并根据您的特定需求或要求处理索引轮换和数据保留。
安全数据湖 维护一个 索引别名 每个索引集,该别名始终指向该索引集中当前处于写入活跃状态的索引。在满足配置的轮换标准(文档数量、索引大小或索引年龄)之前,始终有一个索引用于写入新消息。
后台任务持续检查索引集的轮换标准是否已满足,并在满足时创建并准备新索引。一旦索引准备就绪,索引别名将自动切换到该索引。这意味着所有 安全数据湖 节点都可以向别名写入消息,甚至无需知道索引集中当前处于写入活跃状态的索引是什么。
几乎每个读取操作都是在给定的时间范围内执行的。因为 安全数据湖 按顺序将消息写入搜索后端,所以它可以保留每个索引覆盖的时间范围信息。当提供时间范围时,它会选择要查询的索引列表。如果未提供时间范围,则会在所有已知索引中搜索。
索引和消息的驱逐
有配置设置用于限制 安全数据湖 在给定索引集中管理的最大索引数量。
根据配置的保留策略,当达到配置的最大索引数量时,索引集中最旧的索引将自动关闭、删除或导出。
删除操作由 安全数据湖 主节点在后台线程中执行,该线程持续将索引数量与配置的最大值进行比较:
信息:org.graylog2.indexer.rotation.strategies.AbstractRotationStrategy - 转向索引<graylog_95>应被轮换,现在将转向器指向新索引! 信息:org.graylog2.indexer.MongoIndexSet - 从<graylog_95>切换到<graylog_96>。 信息:org.graylog2.indexer.MongoIndexSet - 创建目标索引<graylog_96>。 信息:org.graylog2.indexer.indices.Indices - 在Elasticsearch中创建了Graylog索引模板"graylog-internal"。 信息:org.graylog2.indexer.MongoIndexSet - 等待索引<graylog_96>的分配。 信息:org.graylog2.indexer.MongoIndexSet - 索引<graylog_96>已成功分配。 信息:org.graylog2.indexer.MongoIndexSet - 将索引别名<graylog_deflector>指向新索引<graylog_96>。 信息:org.graylog2.system.jobs.SystemJobManager - 提交系统作业<f1018ae0-dcaa-11e6-97c3-6c4008b8fc28> [org.graylog2.indexer.indices.jobs.SetIndexReadOnlyAndCalculateRangeJob] 信息:org.graylog2.indexer.MongoIndexSet - 成功将索引别名<graylog_deflector>指向索引<graylog_96>。
索引集配置
有多种与索引集相关的选项 安全数据湖 会将消息存储至搜索后端集群。这些集合可通过导航至 索引与索引集 页面进行管理,路径为 系统 > 索引 .
要创建新集合,请点击页面右上角的 创建索引集 按钮。在此填写以下字段完成索引集创建:
-
标题 :索引集的描述性名称。
-
描述 :供人工阅读的索引集说明。
-
索引前缀 :用于该索引集管理的搜索后端索引的唯一前缀。前缀必须以字母或数字开头,且仅可包含字母、数字、
_,-及+。索引别名将据此命名,例如若索引前缀为bitdefender_deflector则别名即为bitdefender. -
分析器 :(默认:
standard)搜索后端 分析器 用于索引集。 -
索引分片 :(默认值:1)每个索引使用的搜索后端分片数量。
-
索引副本 :(默认值:0)每个索引使用的搜索后端副本数量。
-
轮换后禁用索引优化 :禁用搜索后端 索引优化(强制合并) 在索引轮换后执行。仅当您在优化过程中遇到搜索后端集群性能严重问题时才启用此选项。
-
字段类型刷新间隔 :确定活动写入索引的字段类型信息以秒或分钟为单位的更新频率。
索引轮换配置
您还需为此索引集确定索引轮换策略。默认情况下, 数据分层 在 轮换与保留 下被选中,这是推荐选项。完整了解此方法及不同配置选项,请参阅 数据分层 。
索引保留配置
选择您的索引集保留策略:
-
归档 :在关闭或删除索引前自动进行归档。
-
删除 : 删除搜索后端中的索引 以最小化资源消耗。
维护
保持索引范围同步
安全数据湖 将在新索引创建后自动计算索引范围。
若存储的索引时间范围元数据出现不同步, 安全数据湖 会在网页界面通知您。这种情况可能发生在手动删除索引或移除已“关闭”索引中的消息时。
系统将提供重新生成所有时间范围信息的选项。
您可以在手动删除索引或进行其他可能导致同步问题的更改后,轻松自行重建信息:
$ curl -XPOST http://127.0.0.1:9000/api/system/indices/ranges/rebuild
这将触发一个系统任务:
信息:org.graylog2.indexer.ranges.RebuildIndexRangesJob - 正在重新计算索引范围。
信息:org.graylog2.system.jobs.SystemJobManager - 已提交系统任务<9b64a9d0-dcac-11e6-97c3-6c4008b8fc28> [org.graylog2.indexer.ranges.RebuildIndexRangesJob]
信息:org.graylog2.indexer.ranges.RebuildIndexRangesJob - 正在为默认索引集(graylog2_*)重新计算索引范围:影响5个索引。
信息:org.graylog2.indexer.ranges.MongoIndexRangeService - 在[7ms]内计算了[graylog_96]的范围。
信息:org.graylog2.indexer.ranges.RebuildIndexRangesJob - 为索引graylog_96创建范围:MongoIndexRange{id=null, indexName=graylog_96, begin=2017-01-17T11:49:02.529Z, end=2017-01-17T12:00:01.492Z, calculatedAt=2017-01-17T12:00:58.097Z, calculationDuration=7, streamIds=[000000000000000000000001]}[...]
信息:org.graylog2.indexer.ranges.RebuildIndexRangesJob - 已完成5个索引的范围计算,耗时44ms。
信息:org.graylog2.system.jobs.SystemJobManager - 系统任务<9b64a9d0-dcac-11e6-97c3-6c4008b8fc28> [org.graylog2.indexer.ranges.RebuildIndexRangesJob]在46ms内完成。
手动轮换活动写入索引
有时您可能希望手动轮换活动写入索引,而不等待最新索引满足配置的轮换条件,例如,当您更改了索引映射或每个索引的分片数量时。
您可以通过向 安全数据湖 主节点的REST API发送HTTP请求或通过网页界面完成此操作:
$ curl -XPOST https://***.gravityzone.bitdefender.com/api/system/deflector/cycle

手动轮换会产生类似以下的日志:
信息 : org.graylog2.rest.resources.system.DeflectorResource - 正在为索引集<58501f0b4a133077ecd134d9>循环偏转器。原因:REST请求。 信息 : org.graylog2.indexer.MongoIndexSet - 从<graylog_97>循环至<graylog_98>。 信息 : org.graylog2.indexer.MongoIndexSet - 正在创建目标索引<graylog_98>。 信息 : org.graylog2.indexer.indices.Indices - 已在Elasticsearch中创建Graylog索引模板"graylog-internal"。 信息 : org.graylog2.indexer.MongoIndexSet - 正在等待索引<graylog_98>的分配。 信息 : org.graylog2.indexer.MongoIndexSet - 索引<graylog_98>已成功分配。 信息 : org.graylog2.indexer.MongoIndexSet - 将索引别名<graylog_deflector>指向新索引<graylog_98>。 信息 : org.graylog2.system.jobs.SystemJobManager - 已提交系统作业<024aac80-dcad-11e6-97c3-6c4008b8fc28> [org.graylog2.indexer.indices.jobs.SetIndexReadOnlyAndCalculateRangeJob] 信息 : org.graylog2.indexer.MongoIndexSet - 成功将索引别名<graylog_deflector>指向索引<graylog_98>。 信息 : org.graylog2.indexer.retention.strategies.AbstractIndexCountBasedRetentionStrategy - 索引数量(5)超过限制(4)。正在对1个索引执行保留操作。 信息 : org.graylog2.indexer.retention.strategies.AbstractIndexCountBasedRetentionStrategy - 正在对索引<graylog_94>执行保留策略[org.graylog2.indexer.retention.strategies.DeletionRetentionStrategy] 信息 : org.graylog2.indexer.retention.strategies.DeletionRetentionStrategy - 在23毫秒内完成索引<graylog_94>的保留策略[删除]。
数据分层
安全数据湖 为您提供了将索引集数据分层存储和管理的选项。在设置索引集时,您可以根据数据保留需求建立分层属性。这种方法使您能够有效利用存储,兼顾性能和成本效益。
本文解释了 安全数据湖 如何实现数据分层,以及您需要了解哪些内容来为索引集制定有效的策略。
为何使用数据分层?
借助 安全数据湖 的数据分层功能,每个层级都作为需要以类似方式处理的数据存储库。数据层级可视为具有相同存储和管理规范的数据级别。数据根据使用频率和所需搜索性能水平进行分组。每个层级都有其存储和可访问性标准,这意味着您可以将数据移动到最符合需求的层级。
数据分层有助于降低存储成本,因为不常访问的数据可以存储在成本较低的层级。例如,仅需保留用于合规性检查的数据可以存储在不需要高性能存储的层级,因此成本更低。您可以将成本更高、性能更好的层级保留给更新且更频繁搜索的数据。
数据可以根据以下标准分类到不同层级:
-
性能要求
-
使用频率
-
成本效益
我们推荐数据分层作为自托管安装中存储数据的经济高效方式。数据分层提供三个数据存储层级:热层、温层和归档层。下面将详细描述这些层级。
热层
属于数据流的新 索引 会自动分配到热层,在分层存储中,热层指的是您用于存储的搜索后端集群,并作为所有传入数据的默认层级。热层中的数据易于访问和搜索,但由于必须分配资源来维护,运营成本通常较高。
温层
温层中的数据可搜索,但搜索性能低于热层。温层数据存储在 可搜索快照 中,而不是直接在索引集中。当在温层触发搜索时,系统会将数据从这一恢复层加载到搜索后端集群中。温层适合存储不需要频繁访问的数据,例如最近几周的日志。
可搜索快照索引从存储库读取数据,不会在恢复时将所有数据下载到集群。这种方法使温层成为一种经济高效的存储解决方案。快照存储在温存储库中,可以是Amazon S3存储桶或本地文件系统。可搜索快照以快照格式保留在存储库中,并且是只读的。
归档
安全数据湖 提供 归档 用于存储重要性较低的数据,使其成为存储合规性和历史数据的低成本选择。
归档存储消息,直到您需要将其重新处理至 安全数据湖 进行分析。您可以指示 安全数据湖 自动将日志消息归档为本地文件系统或S3兼容对象存储上的压缩平面文件。消息在保留清理开始前存储,且不会从搜索后端删除。
注意
目前,您可以同时使用数据湖和归档功能长期保存日志数据。两者功能相似,但对于即时价值较低的数据,使用数据湖更具优势。从数据湖检索日志速度更快,因为检索过程是细粒度的。此外,数据湖中的数据经过压缩,因此通常是成本更低的数据存储选择。
设置数据分层
您可以在创建或更新索引集时建立数据分层。实际上,您可以根据所含数据的需求为每个索引集设置不同的分层策略。
在初始设置温层后,建议您监控 安全数据湖 温层节点的系统资源利用率,以确定其文件缓存的最佳磁盘空间量。特别是应密切观察活跃与使用百分比指标(以及文件缓存的总字节数、活跃字节数、已用字节数和驱逐字节数)。
文件缓存使用百分比应低于活跃文件缓存百分比,理想值应控制在70%或更低。关键的是,文件缓存中的活跃字节数应小于已用字节数,而已用字节数应小于文件缓存总字节数,即:
活跃字节数<已用字节数<总字节数
若您通过 安全数据湖 数据节点启用数据分层,则需先为用于查询OpenSearch节点API的第三方工具签发证书颁发机构。签发证书颁发机构的详细说明请参阅 数据节点文档 .
若您使用自管理的OpenSearch,请继续阅读下一节。
获取文件缓存指标
通过
OpenSearch节点状态API
可获取集群统计信息。以下是一个
cURL
命令示例,用于获取前文讨论的文件缓存指标(当OpenSearch指标未被捕获并存储到InfluxDB或Prometheus等时间序列数据库时,此方法尤为实用):
$ curl -s -XGET "http://admin:password@10.0.1.229:9200/_nodes/stats/file_cache?pretty"
以下是上述命令响应输出的示例片段。
"jW4Q6SuXQASt8lM796CBHg" : {
"timestamp" : 1712857680055,
"name" : "10.0.1.229",
"transport_address" : "10.0.1.229:9300",
"host" : "10.0.1.229",
"ip" : "10.0.1.229:9300",
"roles" : [
"搜索"
],
"attributes" : {
"分片索引压力启用" : "true"
},
"file_cache" : {
"timestamp" : 1712857680055,
"active_in_bytes" : 50066073022,
"total_in_bytes" : 128849018880,
"used_in_bytes" : 71497646618,
"evictions_in_bytes" : 0,
"active_percent" : 70,
"used_percent" : 55,
"hit_count" : 83077,
"miss_count" : 877
}
}
供您参考,以下是可通过节点状态API获取的OpenSearch可用指标:
-
nodes.stats.file_cache.active_in_bytes -
nodes.stats.file_cache.total_in_bytes -
nodes.stats.file_cache.used_in_bytes -
nodes.stats.file_cache.evictions_in_bytes -
nodes.stats.file_cache.active_percent -
nodes.stats.file_cache.used_percent -
nodes.stats.file_cache.hit_count -
nodes.stats.file_cache.miss_count
归档
在搜索后端存储大量数据成本高昂。 安全数据湖 允许您将非活跃数据存储至 安全数据湖 归档中以降低存储成本并按需延长保留期。归档索引集时,您可根据多种因素设置 保留周期 。归档索引将在保留周期结束后被删除。
在 安全数据湖 中,您可将索引集归档为本地文件系统的压缩平面文件、S3兼容对象存储或Google云存储(GCS)。请注意归档索引集会在保留清理开始前存储,确保数据不丢失。
注意
归档数据处于非活跃状态,除非恢复否则不可搜索。必要时可通过用户界面重新导入归档索引。数据恢复后,您可通过网页界面搜索分析该数据。详情请参阅 恢复归档 .
选择最大分段大小
归档索引时,归档任务将数据写入分段。 最大分段大小 设置用于限制每个数据分段的体积,从而控制分段文件大小以适应有文件大小限制的工具处理。
达到大小限制后即创建新分段文件。例如:
/path/to/archive/
graylog_201/
archive-metadata.json
archive-segment-0.gz
archive-segment-1.gz
archive-segment-2.gz
配置数据分层索引保留策略
注意
我们的索引轮换与保留模式称为数据分层。数据分层是一种按特定目的分层存储和管理数据的可选方案。详见 数据分层 获取更多信息。
您可以为新建或现有索引集设定数据保留时长。操作步骤:
-
前往 轮换与保留 索引集配置页面的对应版块。
-
切换至 数据分层 选项。
-
选择数据存储的最小和最大天数。
达到最大天数后数据将被删除。如需保留数据,可勾选 删除前归档 .
您还可选择 启用温层存储 。随后可设置数据在热层保留的最短天数,之后将转移至温层。您也可指定温层存储库来存放该索引集。若无现存存储库,可在此菜单新建温层存储库。
选择需归档的数据流
归档设置中的 需归档数据流 功能支持仅归档重要数据 (由您的数据流规则决定) ,而非全量存入 安全数据湖 .
注意
新建数据流将默认自动归档。若需排除新建数据流,请在此配置对话框中禁用其归档。
归档索引集中的数据
现在您已 完成 安全数据湖 归档 设置,即可按需开始归档数据。您可以选择 直接归档索引集 或 定义特定时间范围以设置自动归档 .
为索引集创建新归档
手动归档特定索引集的步骤:
-
导航至 企业版 > 归档 .
-
从下拉菜单中选择目标索引。
-
点击 归档索引 .
已归档的索引集可在界面同页面的 归档目录 中查看。
为索引集设置自动归档
您也可以指定在特定时间归档的索引。这可通过 安全数据湖 界面 或借助 REST API实现 .
通过 安全数据湖 界面
通过REST API实现归档自动化
若需更灵活的操作方式, 安全数据湖 REST API同样支持自动化创建归档。
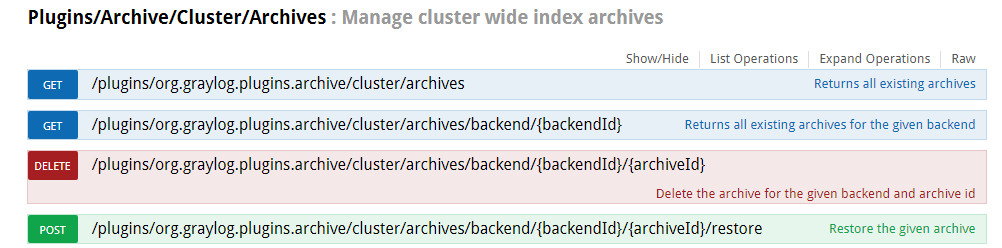
以下示例使用curl命令归档索引。该命令会在
安全数据湖
服务器中启动系统任务,为索引
graylog_386
.
system_job.id
用于检查任务进度。
$ curl -s -u admin -H 'X-Requested-By: cli' -X POST http://127.0.0.1:9000/api/plugins/org.graylog.plugins.archive/archives/graylog_386
输入用户'admin'的主机密码: ***************
{
"archive_job_config" : {
"archive_path" : "/tmp/graylog-archive",
"max_segment_size" : 524288000,
"segment_filename_prefix" : "archive-segment",
"metadata_filename" : "archive-metadata.json",
"source_histogram_bucket_size" : 86400000,
"restore_index_batch_size" : 1001,
"segment_compression_type": "SNAPPY"
},
"system_job" : {
"id" : "cd7ebfa0-079b-11e6-9e1b-fa163e6e9b8a",
"description" : "归档索引并删除",
"name" : "org.graylog.plugins.archive.job.ArchiveCreateSystemJob",
"info" : "正在归档索引中的文档: graylog_386",
"node_id" : "c5df7bff-cafd-4546-ac0a-5ccd2ba4c847",
"started_at" : "2016-04-21T08:34:03.034Z",
"percent_complete" : 0,
"provides_progress" : true,
"is_cancelable" : true
}
}
REST API还可自动化执行其他归档相关任务,例如:
-
恢复和删除归档
-
更新归档配置
建议您探索REST API浏览器,该功能位于 系统 > 节点 .
您可能需要为不同索引设置多种保留期限。某些索引可能仅需保留两个月,而其他索引可能需要更长的存储周期。例如,防火墙日志通常保留两个月,但其他日志消息可能需要保留更长时间以满足合规要求。
保留期限结束后, 安全数据湖 会自动删除较旧的消息。
后续步骤
现在您已创建首个存档,可以开始 恢复归档数据 .
恢复存档
当您完成 配置 安全数据湖 归档功能 并 完成首批数据归档后 ,即可根据需要恢复存档,例如当您需要 搜索 和分析这些数据时。
恢复归档数据
注意
恢复过程会给OpenSearch集群增加负载,因为所有消息都会重新建立索引;建议先测试小型存档以观察集群表现,再恢复大批量数据。同时可通过恢复索引批量大小设置来控制OpenSearch重建索引时的批量大小。
您可通过以下方式恢复归档索引:
请注意 安全数据湖 会将所有索引恢复至 已恢复存档 索引集中,以避免与原始索引(若仍存在)产生冲突。
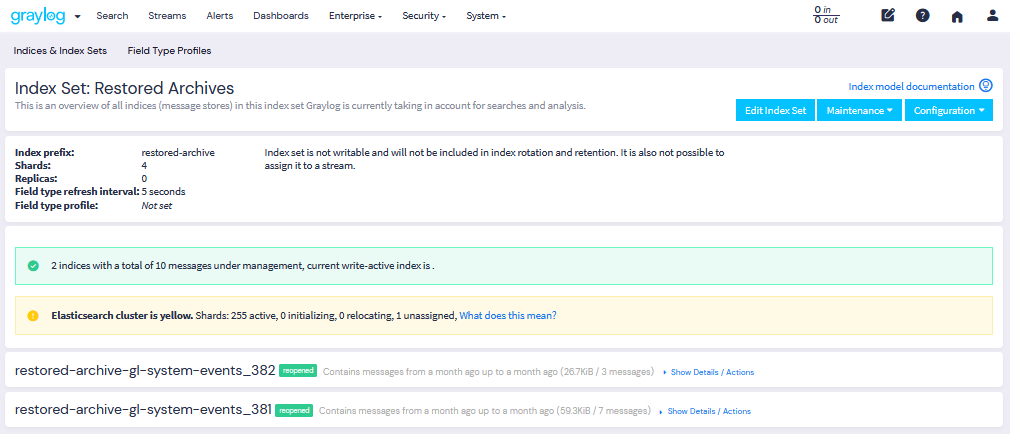
已恢复的索引会被标记为
重新开启
状态,因此它们将
忽略
索引保留任务会跳过这些已恢复的索引,不会将其关闭或删除。因此,当您不再需要已恢复的索引时,必须手动删除它们。
通过 安全数据湖 界面恢复索引
要通过界面恢复归档:
-
导航至 企业版 > 归档 .
-
从 归档目录 部分选择一个索引集。
-
点击 恢复索引 按钮。
您也可以通过搜索框旁的 批量操作 下拉菜单恢复或删除多个索引集。
通过REST API恢复索引
与创建归档类似,您也可以使用REST API将归档索引恢复到OpenSearch集群中:
$ curl -s -u admin -H 'X-Requested-By: cli' -X POST http://127.0.0.1:9000/api/plugins/org.graylog.plugins.archive/archives/graylog_386/restore
输入用户'admin'的主机密码:***************
{
"archive_metadata": {
"archive_id": "graylog_307",
"index_name": "graylog_307",
"document_count": 491906,
"created_at": "2016-04-14T14:31:50.787Z",
"creation_duration": 142663,
"timestamp_min": "2016-04-14T14:00:01.008Z",
"timestamp_max": "2016-04-14T14:29:27.639Z",
"id_mappings": {
"streams": {
"56fbafe0fb121a5309cef297": "nginx请求"
},
"inputs": {
"56fbafe0fb121a5309cef290": "nginx错误日志",
"56fbafe0fb121a5309cef28d": "nginx访问日志"
},
"nodes": {
"c5df7bff-cafd-4546-ac0a-5ccd2ba4c847": "graylog.example.org"
}
},
"histogram_bucket_size": 86400000,
"source_histogram": {
"2016-04-14T00:00:00.000Z": {
"example.org": 227567
}
},
"segments": [
{
"path": "archive-segment-0.gz",
"size": 21653755,
"raw_size": 2359745839,
"compression_type": "SNAPPY"
"checksum": "751e6e76",
"checksum_type": "CRC32"
}
],
"index_size": 12509063,
"index_shard_count": 4
},
"system_job": {
"id": "e680dcc0-07a2-11e6-9e1b-fa163e6e9b8a",
"description": "从归档中恢复索引",
"name": "org.graylog.plugins.archive.job.ArchiveRestoreSystemJob",
"info": "正在从归档索引恢复文档:graylog_307",
"node_id": "c5df7bff-cafd-4546-ac0a-5ccd2ba4c847",
"started_at": "2016-04-21T09:24:51.468Z",
"percent_complete": 0,
"provides_progress": true,
"is_cancelable": true
}
}
返回的JSON负载包含归档元数据和运行索引恢复过程的系统任务描述。
恢复到独立集群
已恢复索引带来的额外负载会降低索引速度。为避免给主OpenSearch集群增加更多负载,您也可以在其他集群上恢复归档索引:
-
将归档索引传输到其他机器。
-
将其放置在配置的后端存储中。
每个索引归档都位于独立目录中,因此若只需转移单个索引,只需将对应目录复制到后端存储。例如:
$ tree /tmp/graylog-archive
/tmp/graylog-archive
├── graylog_171
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
├── graylog_201
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
├── graylog_268
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
├── graylog_293
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
├── graylog_307
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
├── graylog_386
│ ├── archive-metadata.json
│ └── archive-segment-0.gz
└── graylog_81
├── archive-metadata.json
└── archive-segment-0.gz
7 directories, 14 files
在恢复的索引中搜索
搜索查询会自动使用已恢复的索引。每个索引中恢复的消息都带有一个特殊的
gl2_archive_restored
字段,其值为
true
,因此您可以使用类似以下查询来搜索恢复的消息:
_exists_:gl2_archive_restored AND <您的搜索查询>
如果您想从查询中排除所有恢复的消息,请使用:
_missing_:gl2_archive_restored AND <您的搜索查询>
索引器故障
安全数据湖 节点会持续跟踪它们执行的每个索引操作。这有助于确保它们不会无意中丢失任何消息。Web界面可以显示一些失败的写入操作以及失败操作的列表。与Web界面中的任何其他信息一样,这些信息也可以通过REST API获取,因此您可以将其集成到自己的监控系统中。

关于索引失败的信息存储在一个大小有限的MongoDB集合中。大量(数万条)失败消息应该可以容纳其中,但不应该认为这是所有抛出错误的完整集合。
常见的索引器故障原因
在某些情况下可能会出现一些常见的故障。以下是对这些故障的解释:
MapperParsingException
错误消息可能如下所示:
MapperParsingException[无法解析[failure]]; 嵌套: NumberFormatException[对于输入字符串: "some string value"];
您尝试将一个
字符串
写入索引的数字字段。索引器尝试将其转换为数字,但由于
字符串
包含无法转换的字符而失败。
这可能是由于发送带有不同字段类型的GELF消息或提取器尝试写入
字符串
而未先将其转换为数值引起的。
推荐的解决方案是主动决定字段类型
。如果您发送了一个类似
https_response_code
若该字段以数值形式传入,则后续不应更改其类型。
布尔值等其他字段类型同样适用此原则。
需注意索引循环机制的影响。
每个索引中字段首次写入的类型将被锁定。若
安全数据湖
索引发生循环,该索引的字段类型将重置。若首次写入该索引的消息将
https_response_code
定义为
字符串
,则该字段在下一次索引循环前将始终作为
字符串
处理。详见
索引模型
说明文档。
索引器与处理失败索引
安全数据湖 支持将索引和处理失败通知存储至专用故障索引。
失败消息会被记录并聚合至仪表盘,用于设置警报通知,便于分析错误成因。
配置故障处理
新安装的 安全数据湖 默认启用所有故障类型检测。调整设置需:
-
进入 系统 > 配置 .
-
选择 插件 后点击 故障处理 .
-
点击 编辑配置 .

-
勾选或取消勾选每个故障处理功能的复选框。
-
记录索引失败 :存储索引器失败通知并将其记录在专用的 安全数据湖 流中。
-
记录处理失败 :处理失败通知以存储至搜索后端,并将其记录在专用的 安全数据湖 流中。
-
包含失败消息 :在失败通知中显示完整日志消息以供调查。需启用 记录索引失败 或 记录处理失败 以激活此选项。
-
出错时继续处理 :将原始消息与包含具体错误详情的新字段(
gl2_processing_error)一起存储。同时,带有错误详情的失败消息会存入专用的 安全数据湖 流。需启用 记录处理失败 以激活此选项。
-
-
点击“更新配置”保存选择。
启用故障处理后, 系统概览 中的组件会显示失败消息计数器。

常见索引器故障原因
最常见的索引器故障被归类为“MapperParsingException”。
有关此类故障的更多信息,请查阅 常见索引器故障原因。
常见处理失败原因
处理失败可能发生在 安全数据湖 处理栈中,可能有多种原因。以下是最常见原因的列表:
-
RuleStatementEvaluationError-
当管道规则中“then”和“end”值之间的语句出现错误时发生。
-
-
RuleConditionEvaluationError-
当管道规则中“when”和“then”值之间的语句出现错误时发生。
-
-
ExtractorException-
当提取器或转换器错误地读取或推断消息时发生。
-
-
MessageFilterException-
当涉及 安全数据湖 应用程序的后端系统出现故障时发生;可能需要 安全数据湖 支持团队进一步排查。
-
-
InvalidTimestampException-
当尝试在时间戳字段中设置或提取值失败时发生。例如,管道规则在尝试从字符串中提取时间戳并尝试将此空时间戳分配给消息时失败。
-
-
UNKNOWN-
此错误的原因未知,需要进一步调查日志数据。
-