输入
数据洞察 通过输入接收日志数据,输入是系统的入口点。输入不同于 流 (用于路由数据)和 索引集 (用于存储数据)。
输入类别
输入分为两类:
-
监听器(输入配置) - 这类输入在网络端口等待应用程序发送数据至 数据洞察 具体可采用传输控制协议(TCP)或用户数据报协议(UDP),取决于输入类型。
这些输入位于 通用 > 企业版 > 转发器 > 输入配置 > 选择输入配置 > 输入 .
注意
TCP输入可靠性更高,因为每个消息都会在网络层得到确认。UDP输入吞吐量更大但不保证送达。
-
拉取式输入 - 这类输入通过API或其他支持的方法连接至终端并获取日志数据,通常需要对拉取来源的设备或服务进行认证。
此类输入位于 通用 > 系统 > 输入 .
新建输入配置
本文介绍如何创建输入、配置参数并准备接收日志数据。
输入是 数据洞察 接收数据的入口点,定义了 数据洞察 如何与服务器、应用程序及网络设备等数据源通信,使平台能够接收日志消息。
先决条件
确保您拥有一个能够以与所选 数据洞察 输入类型兼容的格式发送数据的日志源。有关具体设置和配置说明,请参阅特定输入类型的文档。
创建新输入
要创建新输入,请按照以下步骤操作:
-
选择屏幕顶部的 系统 菜单。
-
从下拉菜单中选择 输入 。
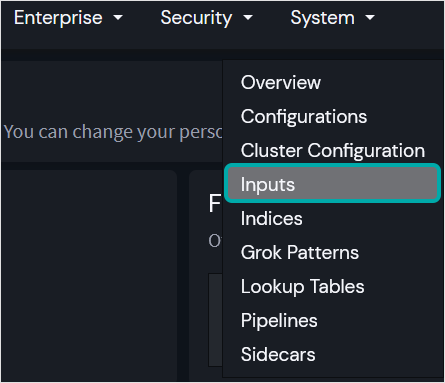
此时将显示 输入 页面。
-
从 选择输入 下拉菜单中选择要配置的输入类型。
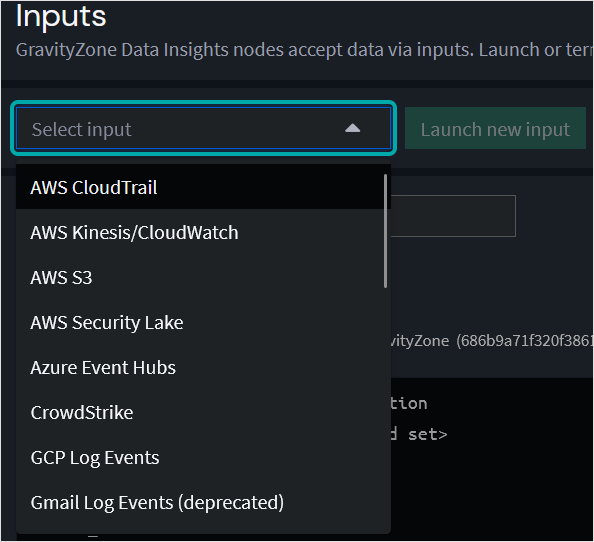
-
选择 启动新输入 .

此时将显示 启动新输入 窗口。
-
填写所有必要信息以配置输入。
-
选择 启动输入 .
新输入将显示在 输入 页面。初始处于停止状态,且未从源接收日志。要完成配置并开始数据路由,请选择 设置输入 位于新创建的输入旁
设置输入
创建输入后,其显示为停止状态且不从源接收日志。要完成配置并启用数据路由,请选择新创建输入旁的“设置输入”。
按以下步骤设置输入:
-
在 本地输入 部分,选择 设置输入 按钮以针对新创建的输入进行操作。

输入设置模式以与所选输入关联的Illuminate处理包列表开始。
这些包包含将传入日志数据转换为通用信息模型(GIM)架构的解析规则,提供规范化和丰富功能。例如,选择 Bitdefender Illuminate包 中的 GravityZone 或 Telemetry 包,将自动应用针对这些数据源的适当解析和丰富逻辑。相比之下,选择GELF HTTP输入不会显示任何 处理 或 聚焦包 ,因为 Illuminate 不提供针对通用GELF输入的包。
此时显示 输入设置向导 窗口。
-
在 选择Illuminate包 选项卡下,选择以下选项之一:
-
选择您要使用的Illuminate包。若内容包或聚焦包已安装,将在列表中显示为不可选选项。
注意
摄取后的日志数据由Illuminate处理,并路由至相应的Illuminate流和索引集。
选择必要的Illuminate处理包后, 数据洞察 将显示与输入相关联的可用内容包和聚焦包。这些包会安装仪表板、Sigma规则及适用于解析为GIM模式日志的事件。
-
若Illuminate内容不存在或不可用,请选择 跳过Illuminate 以配置数据路由偏好。
您现在可选择以下两种选项之一:
提示
建议为每个输入创建新流,以便高效组织和分类日志数据。
-
将数据路由至现有流(选择 选择流 ).
若选择现有流,其附加配置也将生效。若将数据路由至现有流, 数据洞察 会为“所有消息”流附加名为“所有消息路由”的默认不可变管道。该管道不可分离、删除、重命名或修改。
-
创建新流(选择 创建流 ).
路由配置期间,您还可创建管道和索引集。
选择此选项后,按以下步骤操作:
-
输入标题——为流提供描述性名称以便后续识别。
-
添加描述(可选)——包含流的用途或所处理数据类型的详细信息。
-
选择“从默认流中移除匹配项”——启用此选项可防止匹配此流的消息同时出现在默认流中,避免消息重复。
-
选择“为此流创建新管道”——勾选此选项可自动创建专用管道。管道定义消息处理方式(如过滤或富化)。
-
创建新索引集或选择现有索引集。
-
选择 下一步 继续前往 启动 标签页。
-
-
-
-
选择 启动输入 .
-
(可选)选择 启动输入诊断 .
完成输入配置后,将显示输入诊断页面。该页面提供输入当前状态、消息流和故障排除信息的概览,包括输入标题和类型、节点状态、接收消息计数、流量指标以及任何消息错误等详细信息。使用此页面可验证输入是否正常运行以及消息是否按预期接收。
输入类型
输入是 安全数据湖 从各种来源接收日志和事件数据的入口点。每种输入类型决定了数据如何被收集并传输至平台。
输入主要分为两大类:
-
监听器输入 ——这类输入等待来自外部系统的传入消息。它们会打开一个网络端口或端点,持续“监听”设备、代理或应用程序发送的数据。监听器输入通常用于通过TCP、UDP、HTTP或gRPC等协议(例如Syslog、GELF或OpenTelemetry)进行实时日志流传输。
-
拉取输入 ——这类输入主动连接远程服务或API,定期检索日志数据。它们通常用于从云平台、安全工具和SaaS应用程序(例如AWS CloudTrail、Microsoft 365或CrowdStrike)收集数据。
使用适当的输入类型可确保 安全数据湖 能够高效接收并处理来自本地系统和云源的消息。下表列出了所有支持的输入类型、其类别以及在Data Insights环境中的配置位置。
|
输入 |
类型 |
系统下可用 |
转发器下可用 |
|---|---|---|---|
|
拉取 |
是 |
否 |
|
|
拉取 |
是 |
是 |
|
|
拉取 |
是 |
是 |
|
|
拉取 |
是 |
是 |
|
|
拉取 |
是 |
否 |
|
|
监听器 |
否 |
是 |
|
|
监听器(Kafka消费者) |
否 |
是 |
|
|
拉取 |
否 |
是 |
|
|
CEF (CEF AMQP, CEF KAFKA, CEF TCP, CEF UDP) |
监听器 |
否 |
是 |
|
转发器/输出连接器(非输入) |
否 |
是 |
|
|
监听器 |
否 |
是 |
|
|
拉取 |
是 |
否 |
|
|
GELF (TCP/UDP/HTTP) (GELF AQMP, GELF HTTP, GELF TCP, GELF UDP) |
监听器 |
是 |
是 |
|
监听器(Kafka消费者) |
否 |
是 |
|
|
Google Workspace (GCP日志事件) |
拉取 |
是 |
否 |
|
监听器 |
否 |
是 |
|
|
拉取 |
是 |
是 |
|
|
拉取 |
是 |
否 |
|
|
拉取 |
是 |
否 |
|
|
Microsoft Office 365 (Office 365日志事件) |
拉取 |
否 |
是 |
|
拉取 |
是 |
否 |
|
|
NetFlow (NetFlow UDP) |
监听器 |
否 |
是 |
|
拉取 |
是 |
是 |
|
|
OpenTelemetry (gRPC) |
监听器 |
否 |
是 |
|
拉取 |
否 |
是 |
|
|
生成器(测试/模拟) |
是 |
是 |
|
|
原始HTTP (明文AMQP/明文Kafka/明文TCP, 明文UDP) |
监听器 |
是 |
是 |
|
Syslog输入 (AMQP, Kafka, TCP, UDP) |
监听器 |
否 |
是 |
|
拉取 |
是 |
否 |
|
|
拉取 |
是 |
否 |
|
|
拉取 |
是 |
否 |
配置AWS CloudTrail输入
该 AWS CloudTrail 输入允许 数据洞察 从AWS CloudTrail服务读取日志消息。每当您的账户内发生任何操作时,AWS都会生成CloudTrail日志。这些日志可用于跟踪用户活动、API使用情况以及对AWS资源的更改。
要配置AWS CloudTrail输入,请按照以下步骤操作:
1. 确保满足先决条件
-
拥有已启用Amazon CloudTrail的有效AWS账户。
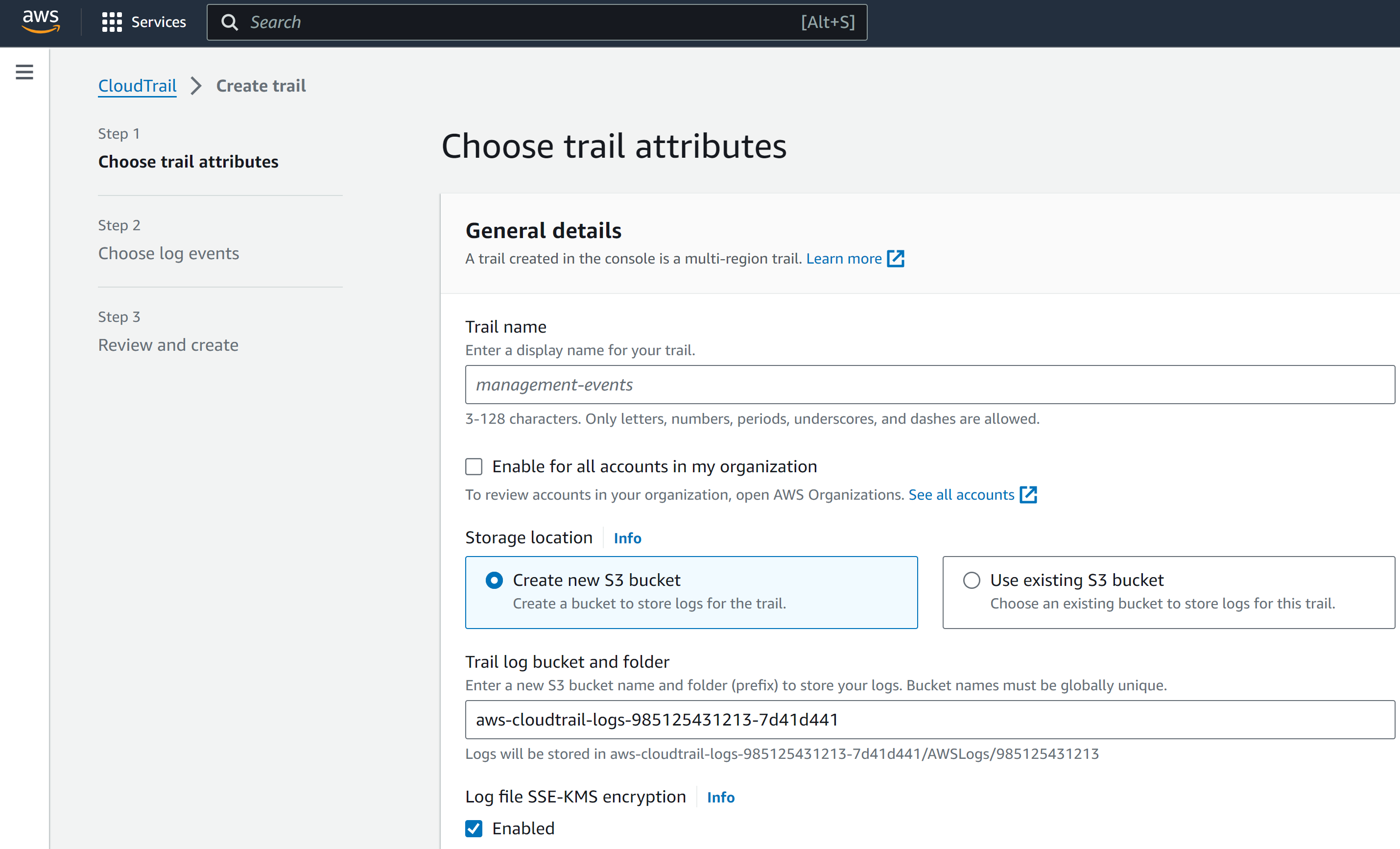
2. 使用AWS CloudTrail创建追踪
-
首先配置 追踪 属性。
-
选择以下选项:
-
追踪名称 :提供一个唯一名称。
-
为我的组织中的所有账户启用: 勾选此复选框以启用/禁用组织中所有账户的追踪。
-
存储位置 :创建一个新的S3存储桶或使用现有S3存储桶。消息内容将存储在该存储桶中。
-
跟踪日志存储桶名称 :输入一个唯一的S3存储桶名称。此位置是CloudTrail写入每条消息有效负载的地方。 数据洞察 从队列接收到SNS消息时,会从此处读取消息内容。
其他设置:
-
日志文件SSE-KMS加密 :此选项默认启用。 AWS KMS 文档提供了更多详细信息。
-
日志文件验证 :启用此选项可将日志摘要传送到您的Amazon S3存储桶。
-
SNS通知传递 :启用。
-
创建新的SNS主题 :为主题指定一个名称(例如
cloudtrail-log-write)或选择现有主题之一。配置 数据洞察 输入时需要此名称。
启用Cloudwatch日志和添加标签是可选的。
-
-
选择要记录的事件类型,例如管理事件、数据事件或洞察事件。
-
查看并完成设置。
3. 为CloudTrail写入通知设置SQS
-
前往 Amazon SQS 并创建一个队列。最初所有设置均可保留默认值。
-
指定队列名称(例如
cloudtrail-notifications)。配置 数据洞察 输入。CloudTrail会将包含S3文件名的通知写入此队列。 -
将SQS队列订阅到您的CloudTrail SNS主题。
4. 确保HTTPS通信
该输入使用AWS SDK与各种AWS资源通信。因此必须允许 数据洞察 服务器与资源之间的HTTPS通信。如果包含 数据洞察 集群的网段通信受限,请确保明确允许访问以下 端点 的通信。
monitoring.<region>.amazonaws.com cloudtrail.<region>.amazonaws.com sqs.<region>.amazonaws.com sqs-fips.<region>.amazonaws.com <bucket-name>.s3-<region>.amazonaws.com
5. 在 数据洞察
中配置输入
|
字段 |
值 |
|---|---|
|
标题 |
为输入输入唯一名称。 |
|
AWS SQS区域 |
选择SQS队列所在的AWS区域。 |
|
AWS S3区域 |
选择存储CloudTrail日志的S3存储桶的AWS区域。 |
|
SQS队列名称 |
输入从SNS接收CloudTrail通知的SQS队列名称。 |
|
启用限流 |
当系统消息处理滞后时停止读取新数据,使 数据洞察 能够跟上进度 |
|
AWS访问密钥 (可选) |
AWS IAM用户的标识符。详情请参阅凭证设置检索顺序文档。 |
|
AWS密钥 (可选) |
具有访问订阅者和SQS队列权限的IAM用户的秘密访问密钥。 |
|
AWS担任角色(ARN) (可选) |
用于跨账户访问时使用此设置。 |
|
覆盖来源 (可选) |
覆盖默认来源值(通常从接收数据包中的主机名派生)。输入自定义字符串以优化来源字段。 |
|
编码 (可选) |
指定输入预期的编码。例如,UTF-8编码的消息不应发送到配置为UTF-16的输入。 |
故障排除
如果CloudTrail输入启动且调试日志显示已接收消息但搜索中未显示任何内容,请验证SQS订阅是否未配置为以 原始格式 .
配置AWS Kinesis/CloudWatch输入
AWS Kinesis / CloudWatch 输入允许 安全数据湖 通过Kinesis从CloudWatch读取日志消息。
要配置AWS Kinesis/CloudWatch输入,请按以下步骤操作:
1. 确保满足先决条件
需要Kinesis将消息流式传输至 安全数据湖 在从CloudWatch读取消息之前,
重要提示
支持以下消息类型:
-
CloudWatch日志 :CloudWatch中的原始文本字符串。
-
CloudWatch流日志 :CloudWatch日志组中的流日志。
-
Kinesis原始日志 :写入Kinesis的原始文本字符串。
2. 设置流程
查阅如何将AWS Kinesis/CloudWatch输入添加到 安全数据湖 。为使此设置按预期运行,必须为授权用户允许推荐策略(参见 权限策略 下文)。
-
执行 AWS Kinesis授权 步骤:
-
添加输入名称、 AWS访问密钥 , AWS密钥 ,并选择 AWS区域 以授权 安全数据湖 .
-
选择 授权并选择流 按钮以继续。
-
-
执行 AWS Kinesis 设置 :
-
在对话框中,选择 自动设置 Kinesis 按钮。
-
输入 Kinesis 流的名称,并从下拉列表中选择一个 CloudWatch 日志组。
-
选择 开始自动设置 .
将出现 Kinesis 自动设置协议提示。
-
阅读协议后,点击 我同意!立即创建这些 AWS 资源 .
自动设置详情及所创建资源的引用。
-
-
点击 继续设置 以继续。
-
在 AWS CloudWatch 健康检查 , Security Data Lake 从 Kinesis 流读取消息并检查其格式。 Security Data Lake 若消息为已知类型,则尝试自动解析。
-
对于 AWS Kinesis 审核 ,请检查并确认输入详情以完成。
权限策略
手动设置流程权限
您可以在 此AWS页面 上找到输入所需的最低权限。该页面还包含这些权限的详细说明和一个示例策略。
自动设置流程权限
自动设置需要手动设置的所有权限以及下面列出的额外权限。
-
iam:CreateRole -
iam:GetRole -
iam:PassRole -
iam:PutRolePolicy -
kinesis:CreateStream -
kinesis:DescribeStream -
kinesis:GetRecords -
kinesis:GetShardIterator -
kinesis:ListShards -
kinesis:ListStreams -
logs:DescribeLogGroups -
logs:PutSubscriptionFilter
AWS S3输入
AWS S3输入会收集发布到Amazon S3存储桶的日志文件。新文件发布时会被自动摄取。支持的格式包括逗号分隔值(CSV)、 安全数据湖 扩展日志格式(GELF)、换行分隔的日志(每行一条消息)和JSON根数组消息(单个JSON数组中的多条日志消息)。该输入使用 Amazon Simple Queue Service (SQS) 存储桶通知来检测何时有新数据可供 安全数据湖 读取。
配置AWS S3输入的步骤如下:
1. 确保满足先决条件
-
一个Amazon Web Services (AWS)订阅。
-
一个已定义的S3存储桶,日志可以写入其中。
2. 创建IAM角色并分配权限
为使 安全数据湖 能够连接至AWS S3,您必须创建一个具有读取目标SQS队列和S3存储桶权限的Identity and Access Management(IAM)角色。输入功能需要以下Amazon权限:
-
s3:GetObject -
sqs:ReceiveMessage
3. 创建并配置SQS队列
创建一个SQS队列供 安全数据湖 订阅以接收待读取新文件的通知。大多数默认选项均可接受。
注意
必须定义访问策略以允许S3存储桶向队列发布通知。以下是授权S3发布通知的示例策略。
此处定义了S3存储桶的创建:
{
"Version": "2012-10-17",
"Id": "示例ID",
"Statement": [
{
"Sid": "s3发布策略",
"Effect": "允许",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "SQS:SendMessage",
"Resource": "arn:aws:sqs:<区域>:<账号>:<队列名称>",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<账号>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:s3:::<S3存储桶名称>"
}
}
}
]
}
注意
有关在Amazon S3控制台中启用和配置通知的更多信息,请参阅 此Amazon知识库文章 .
4. 设置S3存储桶
您需要一个S3存储桶来存储日志消息文件。如果不存在,请按照 此Amazon知识库文章 创建。存储桶创建完成后,按以下步骤启用 事件通知 :
-
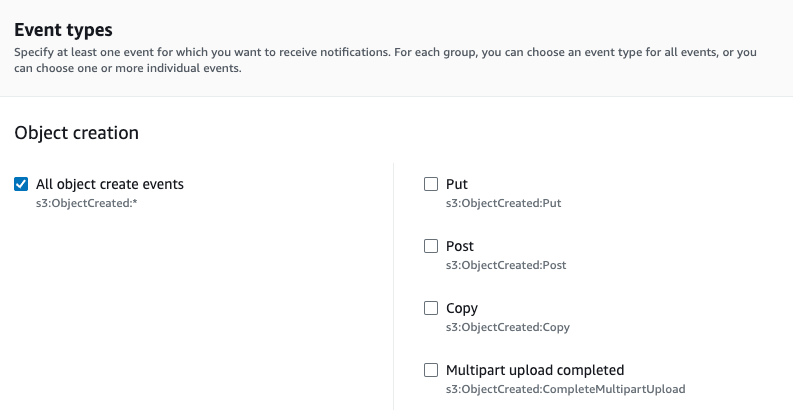
配置通知时,在 事件类型 部分选择 所有对象创建事件 。这将确保无论文件如何创建,输入都能收到通知。
-
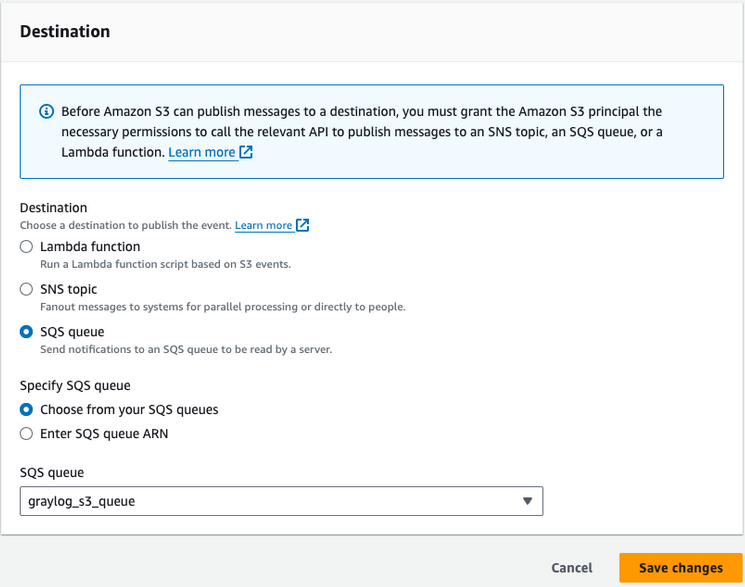
在 目标 部分,选择之前创建的SQS队列。
-
在SQS队列和S3存储桶均设置完成后,测试两者间的通知功能。
注意
有关设置S3存储桶的更多信息,请参阅 这篇亚马逊知识库文章 .
3. 在 安全数据湖
中配置输入
|
字段 |
值 |
|---|---|
|
输入名称 |
为该输入指定唯一名称。 |
|
AWS认证类型 |
该输入支持使用AWS软件开发工具包(SDK)中预定义的认证链进行自动认证。此选项通常用于运行 安全数据湖 的实例附加了IAM策略的情况。输入将按照 AWS文档 . 若选择 密钥与密钥 选项,该输入还支持输入AWS API访问密钥和秘密密钥。 AWS访问密钥ID:为具有S3存储桶及相关SQS队列所需权限的用户生成的访问密钥ID。这些AWS凭证可在 安全数据湖 . |
|
SQS队列名称 |
用于接收S3事件通知的队列名称。 |
|
S3存储桶 |
写入日志文件的S3存储桶。 |
|
S3区域 |
S3存储桶所在的区域。 |
|
AWS担任角色(ARN) |
使用此设置启用跨账户 访问 . |
|
内容类型 |
S3存储桶中日志的格式。同时支持单个CSV字段内的换行值。
|
|
压缩类型 |
日志文件的压缩类型。若日志文件以压缩归档形式写入,则使用此选项。 支持的选项:
|
|
轮询间隔 |
决定 安全数据湖 检查S3存储桶中新数据的频率(以分钟计)。最小允许间隔为5分钟。 指定 安全数据湖 检查S3存储桶中的新数据。最小间隔为5分钟。 |
|
启用限流 |
若启用,则不会从该输入读取新消息,直到 安全数据湖 处理完当前消息负载。 |
AWS安全湖输入
Amazon Security Lake是一项聚合和管理安全日志与事件数据的服务。此集成将安全日志从Amazon Security Lake摄取至 安全数据湖 。有关使用Amazon Security Lake的更多信息,请参阅 亚马逊用户指南 .
配置AWS安全湖输入的步骤如下:
1. 确保满足先决条件
使用AWS安全湖输入需具备已启用Amazon Security Lake的AWS账户,并配置具有适当身份和访问管理(IAM)角色的订阅者。 安全数据湖 随后按配置的时间间隔轮询安全湖并摄取新日志。
更多信息请参阅 Amazon Security Lake 文档。
2. 设置安全湖服务
-
创建AWS账户和管理用户。
-
验证AWS身份和访问管理(IAM)中是否存在 角色 AmazonSecurityLakeMetaStoreManager,若不存在则创建。
-
将 AmazonSecurityLakeMetaStoreManager 角色分配给为该输入配置的用户。
-
在Amazon Security Lake控制台中创建 订阅者 。
-
在 日志和事件来源 页面中,选择要为订阅者启用的数据源。从以下选项中选择:
-
所有日志和事件来源 - 提供对所有事件和日志来源的访问权限。
-
特定日志和事件来源 - 仅提供对所选择来源的访问权限。
-
3. 配置 安全数据湖 输入
通过输入以下值来配置输入:
|
字段 |
值 |
|---|---|
|
输入名称 |
该输入的唯一名称。 |
|
AWS访问密钥ID |
具有订阅者和SQS队列权限的IAM用户的访问密钥ID。 |
|
AWS秘密访问密钥 |
为IAM用户创建的唯一标识符。 |
|
安全数据湖区域 |
创建订阅者的安全数据湖区域。 |
|
SQS队列名称 |
由安全数据湖订阅者创建的SQS队列名称。 |
|
启用限流 |
允许 安全数据湖 在系统处理消息落后并需要追赶时,停止读取此输入的新数据。 |
|
存储完整消息 |
允许 安全数据湖 将原始日志数据存储在每个日志消息的 full_message 字段中。 警告启用此选项可能导致存储的数据量显著增加。 |
支持的日志和事件源
当前该输入支持对以下四种事件源的部分顶级字段解析。其他所有数据均可从 full_message 字段手动解析:
-
CloudTrail - AWS服务中的用户活动和API使用情况。
-
VPC流日志 - 关于VPC中网络接口进出IP流量的详细信息。
-
Route 53 - 由您的Amazon虚拟私有云(Amazon VPC)内资源发起的DNS查询。
-
Security Hub发现项 - 来自Security Hub的Amazon安全发现项。
Azure事件中心输入
Azure事件中心是一项全托管实时数据摄取服务,支持接收来自各类Azure服务的多种事件日志。Azure事件中心输入支持获取事件中心事件并在 安全数据湖 .
Azure事件中心是全托管实时数据摄取服务,用于接收Azure服务的事件日志。Azure事件中心输入从事件中心获取事件并在 安全数据湖 .
配置Azure事件中心输入的步骤如下:
1. 确保满足先决条件
使用Azure事件中心输入需要具备已配置 事件中心 的有效Azure订阅。
2. 在Azure事件中心配置输入访问权限
当Azure事件中心完成配置并开始接收日志事件后,请按以下步骤配置Azure事件中心输入以连接并读取事件:
-
添加一个 共享访问签名(SAS) 策略,以允许输入访问并与您的事件中心通信。
注意
创建策略前请参阅Azure文档了解安全与管理最佳实践。
-
创建策略步骤如下:
-
从屏幕右侧菜单中选择 共享访问策略 。
-
在 事件中心 页面的左侧导航栏选择 共享访问策略 。
-
点击顶部 新建 按钮创建策略。
-
选择 监听 权限( 安全数据湖 仅需从事件中心读取事件)。
-
定义策略后,请记录主或辅助连接字符串。在 安全数据湖 .
3. 配置消费者组
Azure事件中心输入需要配置一个消费者组以从事件中心读取事件。Azure提供了一个 $Default 消费者组,该组足以满足 安全数据湖 的日志摄取需求。若已创建自定义消费者组,可在 安全数据湖 配置中指定。
由于 安全数据湖 的Azure事件中心输入目前仅支持在单个 安全数据湖 节点上运行,因此当前无需配置支持额外并发读取器的消费者组。
4. 配置 安全数据湖 输入
通过输入以下值配置输入:
|
参数 |
描述 |
|---|---|
|
输入名称 |
为该输入指定唯一名称。 |
|
Azure事件中心名称 |
Azure控制台中事件中心的名称。 |
|
连接字符串 |
配置中上述 共享访问签名 策略定义的主或辅助连接字符串。 |
|
消费者组 |
用于读取事件的消费者组。使用 $Default 如果您尚未为事件中心定义自定义消费者组。 |
|
代理URI |
启用后,此选项指向用于Azure通信的HTTPS正向代理URI。 |
|
最大批次大小 |
输入读取事件中心时等待的最大批次大小。输入将阻塞等待,直到达到指定的批次大小后再查询事件中心。 |
|
最长等待时间 |
等待达到上述最大批次大小的最长时间。 |
|
存储完整消息 |
存储从Azure事件中心接收的完整消息负载。 |
代理支持
输入可配置为使用 正向代理 通过代理主机中继与Azure的通信。仅支持支持HTTPS的正向代理。
启用代理支持后,与Azure的连接使用端口
443
并采用
基于WebSockets的AMQP
协议。
存储完整消息
Azure事件中心可存储来自Azure日志数据的完整消息。此选项允许您使用 处理管道 手动解析所有Azure日志消息类型的数据。要启用此功能,请在Azure事件中心集成菜单中选择“存储完整消息”。
Azure事件中心事件源
此输入支持解析并摄取以下Azure事件日志类型。有关将这些服务的事件转发到事件中心的说明,请参阅 Azure文档 .
-
Azure Active Directory(审核和登录日志)
-
Azure审核
-
Azure网络观察程序
-
Azure Kubernetes 服务
-
Azure SQL
Beats 输入
Beats 是一组开源的轻量级数据采集器,作为代理运行在服务器上,专为收集和传输特定类型的操作与安全数据而设计。这些单一用途的代理主要由 Elastic 和开源社区开发。每种 Beat 针对特定用例定制,例如:
|
Beat 名称 |
用途 |
|---|---|
|
|
传输日志文件(如 /var/log/*.log) |
|
|
传输 Windows 事件日志 |
|
|
收集系统及服务指标 |
|
|
|
|
|
监控文件完整性及审计日志 |
|
由社区开发的专用采集器 |
Security Data Lake 中的 Beats 输入 Security Data Lake 可直接接收来自 Beats 采集器的日志数据并进行基础解析。多数情况下,Beats 的 Logstash 输出无需额外配置即可将消息发送至 Security Data Lake 部分 Beats 可能需要调整设置。
Beats 输出:将日志发送至 Security Data Lake
若需将数据从 Beats 发送到 Security Data Lake ,配置Beats使用基于TCP的Logstash输出插件。这与 安全数据湖 中的Beats输入类型兼容,后者实现了与Logstash Beats接收器相同的协议。
提示
: 安全数据湖 的Beats输入仅支持TCP,不支持UDP。请始终将Beats配置为使用TCP输出。
TLS与认证
安全数据湖 的Beats输入支持TLS加密以实现安全的日志传输,并可配置使用客户端证书进行认证。具体设置方法请参考 TLS文档 。
另请参阅:
Beats Kafka输入
Beats Kafka输入支持从Kafka主题收集日志。当Beats数据运输器生成日志并推送到Kafka主题时,该输入会自动摄取并解析这些日志。
先决条件
-
安装Beats、Kafka和Zookeeper。
-
为所有Kafka和Filebeat文件夹提供完全访问权限。
-
按如下方式配置
filebeats.yml文件:filebeat.inputs: - type: log enabled: true paths: - /var/log/syslog output.kafka: hosts: ["your_kafka_host:9092"] # 替换为你的Kafka主机 topic: 'system_logs' # Kafka主题名称 codec.json: pretty: false preset: balanced
-
配置Kafka的
server.properties文件:advertised.listeners=PLAINTEXT://localhost:9092 -
创建Kafka主题:
进入Kafka目录的bin文件夹并执行以下命令:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic <主题名称>
注意
请记得将
localhost
替换为您唯一的IP地址。
安全数据湖 输入配置
当从 安全数据湖 输入 选项卡启动新输入时,可使用以下选项:
|
参数 |
描述 |
|---|---|
|
标题 |
为输入输入一个唯一的名称。 |
|
Bootstrap服务器 |
输入Kafka服务器运行的IP地址和端口。 |
|
Zookeeper地址(可选) |
输入Zookeeper服务器运行的IP地址和端口。 |
|
主题过滤正则表达式 |
输入在
|
|
最小获取字节数 |
输入消息批次在获取前应达到的最小字节大小。 |
|
最大获取等待时间 |
输入获取前的最大等待时间(以毫秒为单位)。 |
|
处理器线程数 |
输入要处理的线程数量。该设置基于主题可用分区的数量。 |
|
自动偏移重置(可选) |
如果Kafka中没有初始偏移量或偏移量超出范围,请从下拉菜单中选择合适的选项。 |
|
消费者组标识符(ID)(可选) |
输入Kafka输入所属的消费者组名称。 |
|
覆盖来源(可选) |
输入从接收数据包派生的默认主机名。仅当需要用自定义字符串覆盖时才设置此来源。 |
|
编码(可选) |
默认编码为UTF-8。如需覆盖默认值,请设置为标准字符集名称。 |
|
自定义Kafka属性(可选) |
通过换行分隔提供额外的Kafka属性。 |
Bitdefender GravityZone输入
Bitdefender GravityZone输入支持通过两种方式收集从Bitdefender GravityZone发布的日志:
两种方法均支持将Bitdefender终端安全数据摄取至 安全数据湖 ,以便通过Illuminate套件进行监控、告警和丰富。
配置Bitdefender GravityZone输入的步骤如下:
1. 确保满足先决条件
对于安全遥测(Syslog)
-
有效的Bitdefender GravityZone订阅。
-
连接到集群的正在运行的转发器。
-
允许入站syslog流量的防火墙规则(默认端口514,或配置的自定义端口)。
-
GravityZone中已配置的安全遥测策略。
-
BEST终端与接收事件的转发器之间的网络连接。
-
TLS为可选配置,但若遥测数据需通过外部或非受信网络传输则建议启用。
事件推送配置(基于HTTPS的CEF协议)
-
有效的Bitdefender GravityZone订阅。
-
GravityZone环境与接收HTTPS请求的本地转发器之间的网络连接。
-
必须支持TLS 1.2或更高版本以实现加密数据传输。
-
必须配置授权标头选项以确保消息的认证投递。
-
需实现以下任一配置方案:
-
确保本地转发器具有公网IP地址,且仅配置为接受来自Bitdefender GravityZone云的连接。
-
部署事件推送连接器,为其分配公网IP地址,并确保其仅接受来自Bitdefender GravityZone云的连接。
随后配置事件推送功能:将日志发送至本地转发器,或直接发送至事件推送连接器。
-
2. 配置GravityZone控制台
方法一 —— Bitdefender安全遥测(原始事件)
Bitdefender安全遥测通过syslog提供原始终端事件数据。这些日志可由 安全数据湖 转发器采集(需配置syslog输入配置文件),该转发器在本地接收遥测事件并将其路由至 安全数据湖 集群。
-
创建syslog输入配置文件
-
进入 企业版 > 转发器 ,然后打开 输入配置 标签页。
-
选择 新建输入配置 并创建新配置文件。
-
在配置文件中,选择 创建输入 并选择 Syslog TCP .
-
指定一个监听端口(例如
1514). -
在 授权头名称 下,输入
authorization. -
输入一个 授权头值 .
-
可选地,根据需要启用TLS或调整缓冲区设置。
-
保存输入配置文件并将其分配给所需的转发器。
-
-
在GravityZone中配置安全遥测
-
登录GravityZone控制台,然后转到 策略 页面。
-
打开将从端点接收数据所使用的策略。
-
转到 代理 > 安全遥测 页面。
-
启用安全遥测,配置SIEM连接设置,并启用您想要跟踪的事件类型。
注意
输入本地转发器的IP地址,以及创建syslog输入配置文件时输入的端口号(步骤1,子步骤d)。
-
-
(可选)验证事件流
-
检查转发器日志或 安全数据湖 消息输入流,以确认遥测事件正在被接收。
-
使用Bitdefender遥测解析包对传入事件进行解析和标准化以便分析。
-
方法2 – Bitdefender GravityZone事件推送(基于HTTPS的JSON格式CEF)
事件推送集成允许GravityZone将通过HTTPS封装的JSON POST请求中的批量CEF格式事件直接发送至输入端点。此方法适用于偏好基于HTTPS出站连接而非syslog传输的环境。
-
启用推送服务
设置GravityZone推送服务 以将日志发送至输入端点。
-
设置API访问权限
注意
GravityZone推送使用API端点进行配置。认证采用Base64编码的API密钥(后跟冒号)实现。
从 我的账户 部分生成API密钥。
-
配置推送设置
使用
setPushEventSettingsAPI请求配置GravityZone将日志发送至 安全数据湖 。 设置以下参数:-
serviceType–cef -
serviceSettings-
url– 输入端点监听的URL(例如https://host:port/bitdefender).注意
端口必须始终设置为
5555。主机必须是本地转发器的IP或主机名。 -
授权——与输入配置中设置的授权头值(步骤1,子步骤f)匹配的密码。 -
需要有效SSL证书–true
-
-
API请求示例:
curl -i -X POST https://cloud.gravityzone.bitdefender.com/api/v1.0/jsonrpc/push \
-H "Authorization: <base64编码的GravityZone API密钥后跟冒号>" \
-H "Content-Type: application/json" \
-d '{
"params": {
"status": 1,
"serviceType": "cef",
"serviceSettings": {
"url": "https://<主机:端口>/bitdefender",
"authorization": "<输入授权头值>",
"requireValidSslCertificate": true
},
"subscribeToEventTypes": {
<包含所需事件类型>
}
},
"jsonrpc": "2.0",
"method": "setPushEventSettings",
"id": "d0bcb906-d0b7-4b5f-b29f-b2e8c459a2df"
}'
完成配置后,使用sendTestPushEvent API请求验证消息是否被 安全数据湖 .
3. 配置 安全数据湖 输入
通过输入以下值配置输入:
|
字段 |
值 |
|---|---|
|
标题 |
用于标识输入的有意义名称。例如: Bitdefender GravityZone——推送输入 . |
|
绑定地址 |
输入监听的IP地址。使用
|
|
端口 |
输入监听的端口号。确保该端口可从Bitdefender GravityZone访问。 |
|
时区 |
传入CEF消息中时间戳的时区。如果不确定,请使用本地时区。示例:
|
|
接收缓冲区大小(可选) |
网络连接的缓冲区大小(字节)。默认值:
|
|
工作线程数(可选) |
用于处理网络连接的线程数。在高吞吐量环境中可增加此值。 |
|
TLS证书文件(可选) |
TLS证书文件的路径。若需启用TLS以建立安全HTTPS连接,则必须提供。 |
|
TLS私钥文件(可选) |
与证书关联的TLS私钥文件路径。 |
|
启用TLS |
为传入HTTPS连接启用TLS。当GravityZone推送服务使用HTTPS时必须启用。 重要必须始终勾选此复选框。 |
|
TLS密钥密码(可选) |
用于解密加密私钥文件的密码(如适用)。 |
|
TLS客户端认证(可选) |
指定在TLS握手期间客户端是否必须通过证书进行认证。 |
|
TLS客户端认证信任证书(可选) |
如需双向TLS认证,包含受信任客户端证书的文件或目录路径。 |
|
TCP保活 |
启用TCP保活数据包以维持持久连接。建议用于长会话。 |
|
启用批量接收 |
支持批量请求中处理以换行符分隔的消息。GravityZone事件推送批次需要此功能。 重要提示必须始终勾选此复选框。 |
|
启用CORS |
为基于浏览器的请求在HTTP响应中添加CORS头。事件推送通常不需要此功能。 |
|
最大HTTP分块大小(可选) |
HTTP请求正文的最大字节数。默认值:
|
|
空闲写入超时(可选) |
关闭空闲客户端连接前的等待时间(秒)。使用
|
|
授权头名称 |
用于身份验证的授权头名称。示例:
|
|
授权头值 |
客户端必须在授权头中包含的密钥值。示例:
|
|
区域设置(可选) |
用于解析CEF消息中时间戳的区域设置。默认值:
|
|
使用完整字段名称 |
启用CEF规范中定义的完整字段名称。建议用于与增强包的兼容性。 |
4. 将Illuminate包与输入集成
配置转发器输入时,请为数据源选择适当的Illuminate处理包。这些包定义了将传入日志数据转换为通用信息模型(GIM)模式的解析和规范化逻辑,从而实现数据增强和关联。
选择一个Bitdefender Illuminate包(例如GravityZone或Telemetry),以自动应用针对这些事件类型的正确增强和映射规则。
注意
您稍后可以在系统 > 转发器 > 输入配置文件中查看或更新Illuminate包分配。
CEF输入
通用事件格式 (CEF)是一种可扩展的、基于文本的格式,旨在支持多种设备类型。CEF定义了包含标准头和可变扩展的日志记录语法,格式为键值对。
大多数网络和安全系统支持Syslog或CEF作为发送数据的方式。 安全数据湖 提供通过UDP、TCP或Kafka和AMQP作为队列系统接收CEF消息的选项。
CEF TCP
要启动新的CEF TCP输入:
-
导航至 系统 > 输入 .
-
选择 CEF TCP 从输入选项中,并点击 启动新输入 按钮。
-
在弹出配置表单中输入您的配置参数。
配置参数
-
标题
-
为输入分配一个标题。 示例 : “XYZ源的CEF TCP输入”
-
-
绑定地址
-
输入此输入监听的IP地址。源系统/数据将日志发送至该IP/输入。
-
-
端口
-
输入与IP地址配合使用的端口。
-
-
时区
-
选择发送CEF消息的系统上配置的时间戳时区。若发送方未包含时区信息,可配置消息到达时应用的时区。此配置不会覆盖时间戳中的时区,但会作为未包含时区信息的消息的默认时区。
-
-
接收缓冲区大小(可选)
-
根据输入处理的流量大小,此值应足够大以确保数据流畅,但也要足够小以避免系统耗费资源处理缓冲数据。
-
-
工作线程数
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。理想线程数取决于 安全数据湖 服务器上的可用CPU核心数。通常建议将工作线程数与CPU核心数对齐,但需与其他服务器需求保持平衡。
-
注意
以下TLS相关设置确保只有有效源能安全地向输入发送消息。
-
TLS证书文件(可选)
-
存储在 安全数据湖 系统上的证书文件。此字段值为
/路径/到/文件)的路径, 安全数据湖 需具备访问权限。
-
-
TLS私钥文件(可选)
-
存储在 安全数据湖 系统上的证书私钥文件。此字段值为
/路径/到/文件)该路径 安全数据湖 应具有访问权限。
-
-
启用TLS
-
若需此输入使用TLS协议,请勾选此选项。
-
-
TLS密钥密码(可选)
-
私钥密码。
-
-
TLS客户端认证(可选)
-
如需强制认证,请将此值设为 可选 或 必选 .
-
-
TLS客户端认证信任证书(可选)
-
客户端(源)证书在 安全数据湖 系统上的存储路径。此字段值为路径(
/路径/到/文件)该路径 安全数据湖 应具有访问权限。
-
-
TCP保活
-
若需输入支持TCP保活数据包以防止空闲连接,请启用此选项。
-
-
空帧分隔符
-
通常无需勾选此选项。每条消息以换行符为分隔符。
-
-
最大消息大小(可选)
-
消息的最大尺寸。默认值通常足够,但可根据消息长度调整。每种输入类型通常有注明消息最大长度的规范说明。
-
-
区域设置(可选)
-
此设置用于确定消息的语言。
-
-
使用完整字段名
-
CEF键名通常用作字段名。如需使用完整字段名,请勾选此选项。
-
CEF UDP
新建CEF UDP输入的步骤:
-
进入 系统 > 输入 .
-
从输入选项中选择 CEF UDP ,点击 新建输入 按钮。
-
在弹出配置表单中输入参数。
配置参数
-
标题
-
为输入分配标题。 示例 : “XYZ源的CEF UDP输入”
-
-
绑定地址
-
指定输入监听的IP地址。源系统/数据将日志发送至该IP/输入。
-
-
端口
-
输入与IP地址配合使用的端口号。
-
-
时区
-
选择发送CEF消息的系统所配置的时区。若发送方未包含时区信息,可配置消息到达时应用的时区。该配置不会覆盖时间戳中的时区,但会作为未含时区信息的消息的默认时区。
-
-
接收缓冲区大小(可选)
-
根据输入处理的流量大小调整该值,需确保数据流畅且避免系统资源过度处理缓冲数据。
-
-
工作线程数
-
此设置控制处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。理想线程数取决于 安全数据湖 服务器的可用CPU核心数,通常建议与CPU核心数保持一致,但需兼顾其他服务器需求保持平衡。
-
-
区域设置(可选)
-
此设置用于确定消息的语言。
-
通过原始HTTP输入接收Cloudflare Logpush日志
来自Cloudflare Logpush服务(通过HTTP目的地)的日志可通过 安全数据湖 的原始HTTP输入功能进行摄取。配置完成后,Logpush将通过HTTP协议向该输入发送以换行符分隔的日志消息批次。
有关此输入的通用信息(包括配置选项)可参阅 原始HTTP输入 文档。
注意
您可参考 使用原始HTTP输入实现GitLab审计事件流 .
先决条件
开始前请确保满足以下条件:
-
需拥有Cloudflare订阅。
-
Cloudflare Logpush HTTP目的地服务必须能转发至您环境中采用TLS加密的端点。详见 使用TLS保护输入 。(注:也可选择通过防火墙或网关路由以满足TLS要求)
-
我们强烈建议在设置原始HTTP输入时启用 授权标头 选项以确保消息请求经过认证。
设置输入
前往 系统 > 输入 并选择 原始HTTP 启动新输入时,必须仔细考虑以下配置设置:
-
绑定地址与端口 :确保Cloudflare能通过您的网络路由到指定的IP地址和端口。请注意,原始HTTP输入会在
/raw根HTTP路径监听请求。 -
TLS设置 :必须为此端点启用TLS,或选择通过防火墙/网关路由以满足TLS使用要求。
-
启用批量接收 :务必勾选此选项,这将确保输入能正确分割Cloudflare发送的换行符分隔的日志批次。
-
授权请求头 :指定用于验证的请求头名称和值,确保输入仅接受通过身份验证的通信。
-
授权请求头名称 :
authorization -
授权请求头值 :选择符合长度与复杂度要求的安全密码,并在Cloudflare中使用相同值进行授权设置。
-
其他可用配置请参阅 原始HTTP输入 文档。除非环境有特殊需求,建议保持默认设置。
在Cloudflare中启用HTTP目标
设置新输入后,需启用Logpush服务将日志发送至 安全数据湖 。具体方法是将 安全数据湖 端点设为Logpush目标,操作指南详见 Cloudflare官方文档 .
注意
请注意 Cloudflare文档中描述的前几个步骤 引导您选择要与Logpush配合使用的相应网站(即域名)。可通过从Cloudflare管理控制台导航栏中选择 网站 并点击 添加域名 来完成此操作。此步骤对于将Cloudflare日志导入 安全数据湖 !.
当系统提示您输入原始HTTP输入监听请求的URI时,请确保URL包含
/raw
根路径。例如:
https://graylog-host:port/raw?header_Authorization=<Graylog输入授权头值>
CrowdStrike输入
该输入从CrowdStrike API获取数据并摄取至 安全数据湖 以进行安全事件分析。
配置CrowdStrike输入需遵循以下步骤:
1. 确保满足先决条件
为允许 安全数据湖 从CrowdStrike拉取数据,需在CrowdStrike Falcon UI中创建具有必要权限的API客户端。
更多信息请参阅 CrowdStrike文档 .
注意
您必须具有Falcon管理员角色才能查看、创建或修改API客户端或密钥。密钥仅在创建新API客户端或重置时显示。
2. 配置CrowdStrike
按以下步骤定义CrowdStrike API客户端:
-
登录Falcon UI。
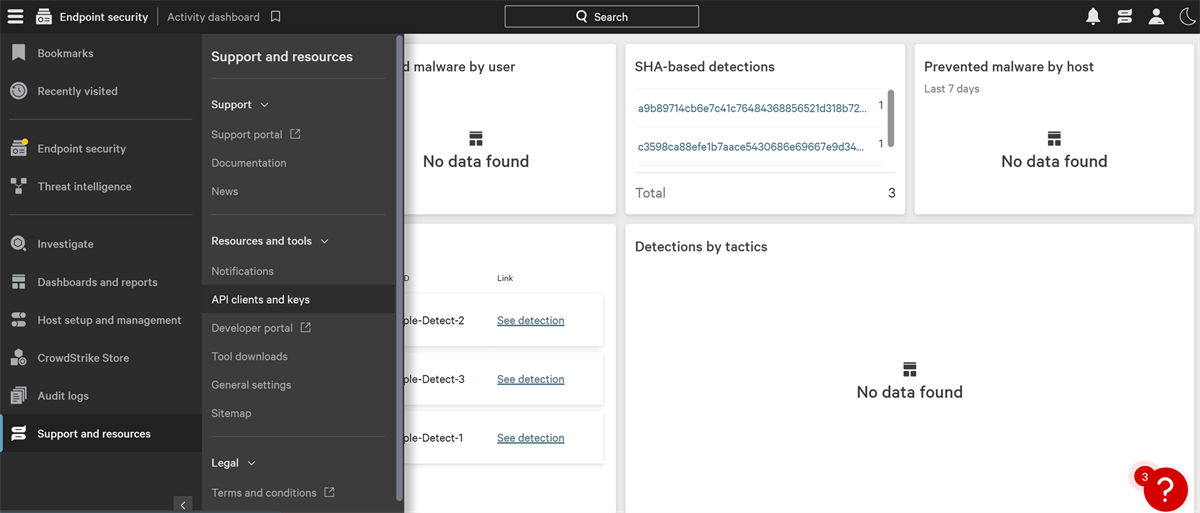
-
从屏幕左侧菜单中选择 支持与资源 ,然后 API客户端与密钥 .
-
选择 添加新API客户端 .
-
为新API客户端输入名称和描述。
-
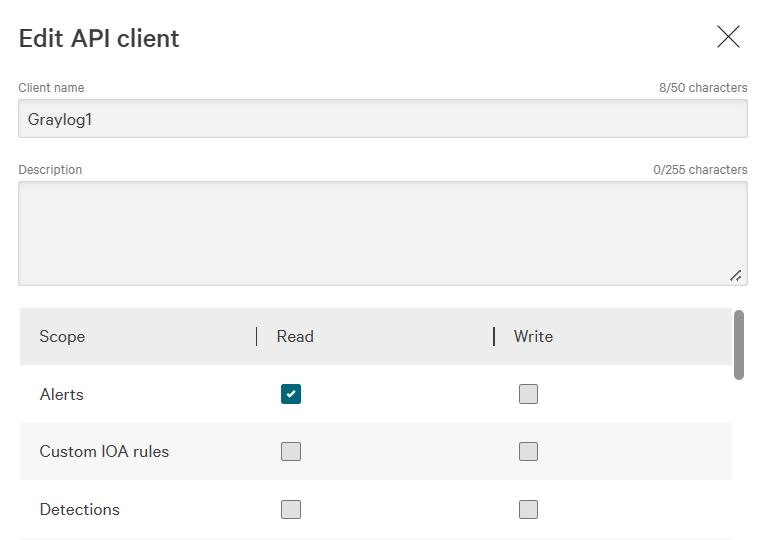
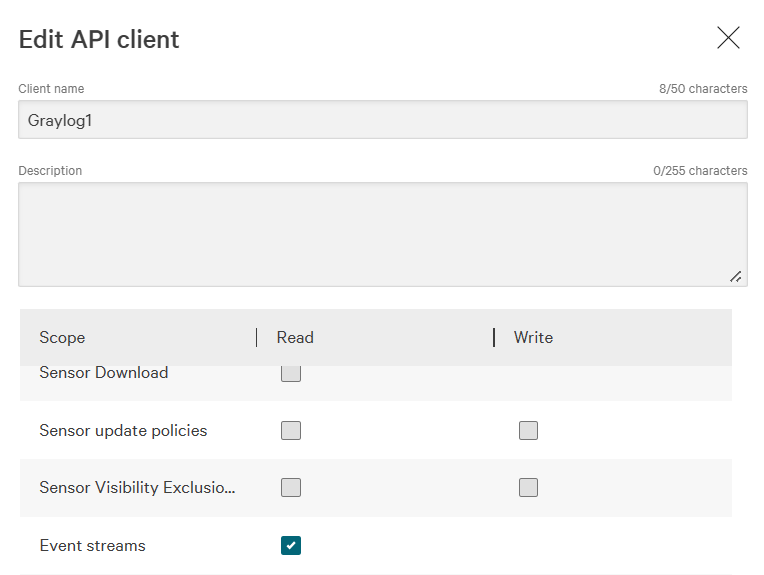
在 API权限范围 部分,通过勾选 警报 和 事件流 对应的 读取 复选框,授予读取权限。
-
选择 保存 .
将显示客户端ID和客户端密钥
注意
客户端密钥仅显示一次且必须安全存储。若丢失则需重置,且所有使用该密钥的应用必须更新为新凭证。
-
3. 在 安全数据湖
中配置输入
|
字段 |
值 |
|---|---|
|
输入名称 |
为该输入指定唯一名称。 |
|
CrowdStrike客户端ID |
在CrowdStrike配置过程中获取的客户端ID。 |
|
客户端密钥 |
从CrowdStrike配置中获取的客户端密钥。 |
|
用户区域 |
CrowdStrike用户账户所在区域。 |
|
存储完整消息 |
允许
安全数据湖
将原始日志数据存储于每条日志消息的
警告启用此选项可能导致存储数据量显著增加。 |
|
检查点间隔 |
指定 安全数据湖 为CrowdStrike数据流记录检查点的频率(以秒为单位),默认值为30秒。 |
GELF
该 安全数据湖 扩展日志格式(GELF)是一种规避传统纯文本syslog缺陷的日志格式:
-
长度限制为1024字节,不足以容纳回溯等负载数据。
-
结构化syslog中无数据类型区分,数字与字符串无法辨别。
-
RFC标准虽严格,但现存syslog方言众多,难以全部解析。
-
不支持压缩。
syslog适用于记录机器或网络设备的系统消息,而GELF则是应用程序内部记录的理想选择。多种编程语言和日志框架均提供相关库和附加器,易于实现。GELF可通过UDP传输,能将每个异常作为日志消息无间断地发送至您的 安全数据湖 集群,避免超时、连接问题或日志类内部故障导致应用程序中断。
基于UDP的GELF
分块传输
UDP数据报的大小限制为65536字节。某些 安全数据湖 组件的处理上限为8192字节。大量压缩信息可以满足此大小限制,但若需发送更多信息,这就是为什么 安全数据湖 支持分块GELF。
您可以通过在GELF消息前添加字节头来定义消息块,包括消息ID和序列号以便后续重组消息。
TCP本可在传输层解决此问题,但它存在更难处理的问题:连接缓慢、超时及其他网络问题。
UDP可能导致消息丢失,而TCP若未精心设计则可能拖垮整个应用。
当然,在高流量环境中TCP是明智之选。许多GELF库同时支持TCP和UDP传输,部分还支持HTTPS。
在GELF消息前添加以下结构以实现分块:
-
分块GELF魔数字节 - 2字节:
0x1e0x0f -
消息ID - 8字节: 必须与此消息所有分块相同。用于标识整个消息并重组分块。例如可从毫秒时间戳+主机名生成。
-
序列号 - 1字节: 此分块的序列号从0开始,且必须小于序列总数。
-
序列总数 - 1字节: 此消息的分块总数。
所有分块 必须 在5秒内到达,否则服务器将丢弃已到达或正在到达的分块。 不得 包含超过128个分块。
注意
请注意
安全数据湖
的UDP输入使用了
SO_REUSEPORT
套接字选项,该功能需Linux内核版本3.9以上。因此UDP输入在3.9之前的内核版本上无法工作。
压缩
当使用UDP作为传输层时,GELF消息可以未经压缩发送,也可以用GZIP或ZLIB压缩后发送。
安全数据湖 节点会自动检测GELF魔术字节头中的压缩类型。
您可以选择是否牺牲少量CPU负载来节省网络流量。GZIP是协议的默认选项。
通过TCP传输GELF
目前,GELF TCP仅支持未压缩且未分块的负载。在同一TCP连接中发送时,每条消息必须以空字节(
\0
)作为分隔符。
警告
由于使用空字节(\0)作为帧分隔符,GELF TCP不支持压缩功能。
GELF负载规范
版本1.1(2013年11月)
GELF消息是包含以下字段的JSON字符串:
-
版本
字符串(UTF-8编码)-
GELF规范版本——"1.1"; 必须 由客户端库设置。
-
-
主机
字符串(UTF-8编码)-
发送此消息的主机、来源或应用程序名称; 必须 由客户端库设置。
-
-
简短消息
字符串(UTF-8编码)-
简短的描述性消息; 必须 由客户端库设置。
-
-
完整消息
字符串(UTF-8编码)-
可包含回溯信息的长消息;可选。
-
-
时间戳
数字-
自UNIX纪元以来的秒数,可包含表示毫秒的小数位; 应 由客户端库设置。若缺失,时间戳将设为当前时间(now)。
-
-
级别
数字-
等同于标准syslog级别的数值;可选。默认为1(ALERT)。
-
-
设施
字符串(UTF-8)-
可选,已弃用。请作为附加字段发送。
-
-
行号
数字-
引发错误的文件行号(十进制);可选,已弃用。请作为附加字段发送。
-
-
文件
字符串(UTF-8)一个-
引发错误的文件(可包含路径);可选,已弃用。请作为附加字段发送。
-
-
_[附加字段]
字符串(UTF-8)或数字-
所有以下划线(
_)为前缀发送的字段均视为附加字段。字段名允许使用任何单词字符(字母、数字、下划线)、连字符和点号。验证正则表达式为:^[\\w\\.\\-]*$。各库不应允许以附加字段形式发送id(_id). 安全数据湖 服务器节点会自动忽略此字段。
-
示例负载
这是一个GELF消息负载示例。任何 安全数据湖 服务器节点都会接受并将其存储为一条消息,无论是以GZIP/ZLIB压缩格式还是通过普通套接字无换行符的未压缩形式发送。
注意
换行符必须使用
\n
转义序列表示,以确保负载符合
RFC 7159
.
{
"version": "1.1",
"host": "example.org",
"short_message": "一条帮助您识别当前情况的简短消息",
"full_message": "此处为回溯信息\n\n更多内容",
"timestamp": 1385053862.3072,
"level": 1,
"_user_id": 9001,
"_some_info": "foo",
"_some_env_var": "bar"
}
注意
目前, 安全数据湖 中的GELF服务器实现不支持布尔值。布尔值在摄入时将被丢弃( 供参考 ).
通过Netcat发送UDP格式的GELF消息
向GELF UDP输入发送示例消息(运行在主机
datainsights.example.com
的12201端口):
echo -n '{ "version": "1.1", "host": "example.org", "short_message": "一条简短消息", "level": 5, "_some_info": "foo" }' | nc -w0 -udatainsights.example.com 12201
通过Netcat发送TCP格式的GELF消息
向GELF TCP输入发送示例消息(运行在主机
datainsights.example.com
端口12201上):
echo -n -e '{ "version": "1.1", "host": "example.org", "short_message": "简短消息", "level": 5, "_some_info": "foo" }'"\0" | nc -w0datainsights.example.com 12201
使用Curl发送GELF消息
向GELF输入发送示例消息(运行于
https://datainsights.example.com:12201/gelf
):
curl -X POST -H 'Content-Type: application/json' -d '{ "version": "1.1", "host": "example.org", "short_message": "简短消息", "level": 5, "_some_info": "foo" }' 'http://datainsights.example.com:12201/gelf'
GELF输入
该 安全数据湖 扩展日志格式(GELF) 是一种避免传统纯文本Syslog缺陷的日志格式,非常适合从应用层记录日志。它支持可选压缩、分块,最重要的是具有明确定义的结构。GELF消息的输入方式可以是UDP、TCP或HTTP,此外还支持队列。
部分应用如 Docker可原生发送GELF消息 。同样, fluentd也支持GELF .
现有 数十种GELF库 适用于多种框架和编程语言助您快速上手。更多关于GELF的细节请参阅规范文档。
注意
此输入监听HTTP POST请求的
/gelf
路径。
GELF HTTP
您可以通过HTTP发送所有GELF类型,包括未压缩的GELF(即纯JSON字符串)。此输入支持配置授权头信息,以添加类似密码的保护机制。配置后,任何发起请求的客户端必须在每次请求时提供正确的授权头名称和值,请求才会被接受。
在 启动新输入后 ,根据您的偏好配置以下字段:
-
全局
-
勾选此复选框可在所有 安全数据湖 节点上启用该输入,或保持未勾选以在特定节点上启用。
-
-
标题
-
为输入分配一个唯一标题。 示例 : “XYZ源的GELF TCP输入”。
-
-
绑定地址
-
输入此输入监听的IP地址。源系统/数据将日志发送到此IP/输入。
-
-
端口
-
输入与IP地址配合使用的端口。
-
-
接收缓冲区大小(可选)
-
根据输入处理的流量大小,此值应足够大以确保数据正常流动,但也要足够小以避免系统因处理缓冲数据而消耗过多资源。
-
-
工作线程数(可选)
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。配置的理想线程数取决于您的 安全数据湖 服务器上的可用CPU核心数。通常建议将工作线程数与CPU核心数对齐,但需与其他服务器需求保持平衡。
-
注意
以下TLS相关设置可确保只有有效源才能安全地向输入发送消息。
-
TLS证书文件(可选)
-
存储在 安全数据湖 系统。该字段值为一个路径(
/路径/到/文件), 安全数据湖 应有权访问。
-
-
TLS私钥文件(可选)
-
存储在 安全数据湖 系统上的证书私钥文件。该字段值为一个路径(
/路径/到/文件), 安全数据湖 应有权访问。
-
-
启用TLS
-
若需此输入使用TLS则勾选。
-
-
TLS密钥密码(可选)
-
私钥密码。
-
-
TLS客户端认证(可选)
-
若要求向此输入发送日志的消息源进行身份验证,请设为可选或必需。
-
-
TLS客户端认证信任证书(可选)
-
客户端(消息源)证书在 安全数据湖 系统上的存储路径。该字段值为一个路径(
/路径/到/文件), 安全数据湖 应有权访问。
-
-
TCP保活
-
若需输入支持TCP保活数据包以防止空闲连接,请启用此选项。
-
-
启用批量接收
-
启用此选项以接收由换行符(\n 或 \r\n)分隔的批量消息。
-
-
启用CORS
-
启用跨源资源共享(CORS)以配置服务器在HTTP响应中发送特定头部,指示浏览器允许跨源请求。
-
-
最大HTTP分块大小(可选)
-
对于大数据,通常采用分块处理(例如8KB或64KB的分块)以防止缓冲区溢出。最大HTTP分块大小为65536字节。
-
-
写入器空闲超时(可选)
-
服务器在因不活动而关闭连接前,等待客户端向输出流发送数据的最大时间。
-
-
授权头部名称(可选)
-
指定自定义授权头部名称,可选择为所有接收的消息强制实施身份验证。这是为此输入添加类似密码安全性的方法。
-
-
授权头部值(可选)
-
指定授权头部值,可选择为所有接收的消息强制实施身份验证。
-
-
编码(可选)
-
所有消息需支持为输入配置的编码。例如,UTF-8编码的消息不应发送到配置为支持UTF-16的输入。
-
-
覆盖来源(可选)
-
默认情况下,消息将来源字段解析为日志消息中提供的主机名。但如果要覆盖输出非标准或不可配置主机名的设备的此设置,可在此处设置替代来源名称。
-
-
解压后大小限制
-
解压后消息的最大大小。
-
启动GELF HTTP输入后,可使用以下端点发送消息:
http://graylog.example.org:[端口]/gelf (POST)
尝试使用curl发送示例消息:
curl -XPOST http://graylog.example.org:12202/gelf -p0 -d '{"short_message":"Hello there", "host":"example.org", "facility":"test", "_foo":"bar"}'
通过常见HTTP头部支持保持连接和压缩。服务器将返回
202Accepted
表示消息已接受处理。
为HTTP GELF输入启用批量接收选项
安全数据湖 为用户提供通过HTTP GELF输入启用批量接收消息的选项,允许接收由换行符分隔的批量消息。
启用此选项后,输入将自动分隔由换行符(\n 或 \r\n)分隔的多个GELF消息。
示例curl请求:
curl -XPOST -v http://127.0.0.1:12202/gelf -p0 \
-d $'{"short_message":"批量消息1", "host":"example.org", "facility":"test", "_foo":"bar"}\r\n\
{"short_message":"批量消息2", "host":"example.org", "facility":"test", "_foo":"bar"}\r\n\
{"short_message":"批量消息3", "host":"example.org", "facility":"test", "_foo":"bar"}\r\n\
{"short_message":"批量消息4", "host":"example.org", "facility":"test", "_foo":"bar"}\r\n\
{"short_message":"批量消息5", "host":"example.org", "facility":"test", "_foo":"bar"}'
注意
HTTP GELF输入已支持Transfer-Encoding: chunked传输方式,该支持现已扩展至新的批量接收功能(当新的
启用批量接收配置
选项开启时)。
警告
每条GELF消息必须格式化为有效JSON(内部不含换行符)。尝试向该输入提交格式化JSON将导致错误。
GELF TCP
在 启动新输入后 ,根据您的偏好配置以下字段:
-
标题
-
为该输入分配唯一标题。 示例 : “XYZ源的GELF TCP输入”
-
-
绑定地址
-
输入该输入监听的IP地址。源系统/数据将日志发送至此IP/输入。
-
-
端口
-
输入与IP地址配合使用的端口号。
-
-
接收缓冲区大小(可选)
-
根据输入处理的流量大小,该值应足够大以确保数据正常流动,同时足够小以避免系统耗费资源处理缓冲数据。
-
-
工作线程数
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。理想线程数取决于您的 安全数据湖 服务器上的可用CPU核心数。通常建议将工作线程数与CPU核心数对齐,但需兼顾其他服务器需求。
-
注意
后续TLS相关设置可确保只有有效源能安全地向输入发送消息。
-
TLS证书文件(可选)
-
存储于 安全数据湖 系统中的证书文件。该字段值为一个路径(
/path/to/file), 安全数据湖 应具有访问权限。
-
-
TLS私钥文件(可选)
-
存储于 安全数据湖 系统中的证书私钥文件。该字段值为一个路径(
/path/to/file), 安全数据湖 应具有访问权限。
-
-
启用TLS
-
若该输入需使用TLS则勾选。
-
-
TLS密钥密码(可选)
-
私钥密码。
-
-
TLS客户端认证(可选)
-
若要求向此输入发送日志的消息源进行身份认证,请设置为可选或必需。
-
-
TLS客户端认证信任证书(可选)
-
客户端(消息源)证书在 安全数据湖 系统中的存储路径。该字段值为一个路径(
/path/to/file), 安全数据湖 应具有访问权限。
-
-
TCP保活
-
如需输入支持TCP保活数据包以防止空闲连接,请启用此选项。
-
-
空帧分隔符
-
此选项通常保持未勾选状态。换行符是每条消息的分隔符。
-
-
最大消息大小
-
消息的最大尺寸。默认值通常足够,但可根据消息长度调整。每种输入类型通常会有说明消息最大长度的规范。
-
-
覆盖来源
-
默认情况下,消息将日志中提供的hostname解析为来源字段。若需为输出非标准或不可配置主机名的设备覆盖此设置,可在此指定替代来源名称。
-
-
编码
-
所有消息需支持输入配置的编码。UTF-8编码的消息不应发送至配置为支持UTF-16的输入。
-
-
解压大小限制
-
消息解压后的最大尺寸。
-
GELF UDP
在 启动新输入后 ,根据您的偏好配置以下字段:
-
全局
-
勾选此框可在所有 安全数据湖 节点启用该输入,或保持未勾选以在特定节点启用。
-
-
标题
-
为输入分配唯一标题。 示例 : “XYZ源的GELF UDP输入”
-
-
绑定地址
-
输入该输入将监听的IP地址。源系统/数据将日志发送至此IP/输入。
-
-
端口
-
输入与IP地址配合使用的端口号。
-
-
接收缓冲区大小(可选)
-
根据输入所接收的流量大小,此值应足够大以确保数据正常流动,同时也要足够小以避免系统耗费资源处理缓冲数据。
-
-
工作线程数
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。配置的理想线程数取决于您的 安全数据湖 服务器上的可用CPU核心数。通常建议初始设置使工作线程数与CPU核心数一致。但需注意与其他服务器需求保持平衡。
-
-
覆盖来源
-
默认情况下,消息会将来源字段解析为日志消息中提供的主机名。但若需为输出非标准或不可配置主机名的设备覆盖此设置,可在此指定替代来源名称。
-
-
编码
-
所有消息均需支持输入配置的编码格式。UTF-8编码的消息不应发送至配置为支持UTF-16的输入。
-
-
解压大小限制
-
消息解压后的最大尺寸。
-
GELF Kafka输入
GELF Kafka输入支持借助Filebeats从Kafka主题收集日志。系统生成日志并推送至Kafka主题后,该输入将自动获取这些日志。
先决条件
-
安装Beats、Kafka和Zookeeper。
-
为所有Kafka和Filebeats文件夹授予完全访问权限。
-
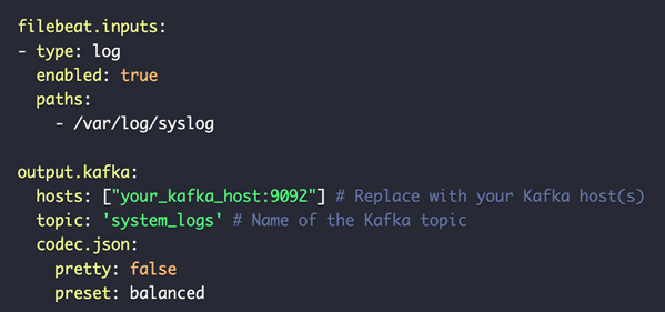
按如下方式配置
filebeats.yml文件:注意
请将localhost替换为您的唯一IP地址。
-
配置Kafka
server.properties文件advertised.listeners=PLAINTEXT://localhost:9092. -
创建Kafka主题。
-
进入Kafka目录的bin文件夹并执行以下命令:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic <主题名称>
-
创建GELF Kafka输入
启动新的GELF Kafka输入:
-
导航至 系统 > 输入 .
-
从输入选项中选择 GELF Kafka 并点击 启动新输入 按钮。
-
在弹出配置表单中输入您的配置参数。
配置参数
-
标题
-
为输入分配标题。例如:“XYZ源的GELF Kafka输入”。
-
-
Bootstrap服务器(可选)
-
输入Kafka服务器的IP地址和端口。
-
-
ZooKeeper地址(仅限旧版模式)(可选)
-
输入Kafka服务器的IP地址和端口。
-
-
主题过滤正则表达式
-
输入在
filebeats.yml文件中配置的主题名称过滤器。
-
-
最小获取字节数
-
输入获取前消息批次应达到的最小字节大小。
-
-
最大获取等待时间(毫秒)
-
输入获取前的最大等待时间(毫秒)。
-
-
处理器线程数
-
输入要处理的线程数。这基于主题可用的分区数量。
-
-
允许限制此输入
-
若启用此选项,则在此输入源的消息负载处理完毕前,将不再读取新消息。 安全数据湖 该配置参数通常适用于从文件或AMQP、Kafka等消息队列系统读取的输入源。若需定期轮询外部系统(如通过HTTP),则应保持此选项禁用状态。
-
-
自动偏移重置(可选)
-
当Kafka中无初始偏移量或偏移量越界时,请从下拉菜单中选择相应选项。
-
-
消费者组ID(可选)
-
输入此Kafka输入源所属的消费者组名称。
-
-
覆盖来源(可选)
-
输入从接收数据包派生的默认主机名。仅当需要自定义字符串覆盖时才设置此来源。
-
-
编码格式(可选)
-
默认编码为UTF-8。如需覆盖默认值,请设置为标准字符集名称。所有消息均需支持输入源配置的编码格式。UTF-8编码消息不应发送至配置为支持UTF-16的输入源。
-
-
解压后大小限制
-
消息解压后的最大尺寸。
-
-
自定义Kafka属性(可选)
-
通过换行分隔的方式为Kafka提供额外属性。
-
Google Workspace输入源
该输入源通过 Google Workspace日志与报告导出功能 从Google BigQuery采集日志。当用户在Docs、Gmail或Chat等服务中执行操作时,相关日志条目会自动推送至BigQuery并完成采集。采集完成后,输入源将删除已消费的日志。
配置Google Workspace输入源需遵循以下步骤:
1. 确保满足先决条件
需持有有效的 Google Workspace 及 Google Cloud 订阅,并安装Illuminate Google Workspace内容包。
2. 配置Google Cloud
按以下步骤配置与输入源集成的Google Cloud环境:
3. 配置Google Workspace
完成Google Cloud配置后,登录Google Workspace管理控制台并启用BigQuery导出选项。
更多信息请参阅 Google官方文档 .
4. 配置 安全数据湖 输入参数
通过填写以下值配置输入模块:
|
字段 |
值 |
|---|---|
|
输入名称 |
输入模块的唯一标识名 |
|
服务账号密钥 |
在Google Cloud设置过程中导出的密钥JSON文件。 注意需要此密钥以授权输入连接至BigQuery。 |
|
BigQuery数据集名称 |
在BigQuery中配置的数据集名称。 |
|
需收集的日志类型 |
选择所需的Google Workspace日志类型。 |
|
轮询间隔 |
决定(以分钟为单位)检查 安全数据湖 在BigQuery表中获取新数据的频率。 |
|
高级选项 |
|
|
启用限流 |
若启用,则在此输入中不会读取新消息,直到 安全数据湖 处理完当前消息负载。 |
|
页面大小 |
设置每页查询结果返回的日志最大数量。默认设置为1000。 |
|
滞后时间偏移量 |
设置滞后时间(小时),因为活动数据填充至BigQuery表存在初始延迟。 |
|
存储完整消息 |
将完整的JSON工作空间日志消息存储于 full_message 字段中。 警告启用此选项可能导致存储数据量显著增加。 |
IPFIX输入
IPFIX输入允许 安全数据湖 读取IPFIX日志。该输入支持所有标准 默认支持的IANA字段 。
IPFIX字段定义
所有需要收集的额外厂商/硬件特定字段必须在JSON文件中定义。该文件需提供 私有操作编号 以及待收集的附加字段定义。请参照以下示例构建JSON文件。
JSON文件示例
在IPFIX字段定义选项中提供包含额外收集字段的JSON文件路径。
{
"enterprise_number": 私有企业编号,
"information_elements": [
{
"element_id": 元素ID编号,
"name": "定义名称",
"data_type": "抽象数据类型"
},
...
...
...
{
"element_id": 元素ID编号,
"name": "定义名称",
"data_type": "抽象数据类型"
}
]
}
HTTP API输入的JSON路径
带JSON路径的HTTP API输入会读取REST资源的JSON响应并提取字段值,将其存储为 安全数据湖 消息。
注意
该输入仅能提取JSON原始值(如数字、文本或字符串),无法处理对象或数组。
配置HTTP API输入的JSON路径需遵循以下步骤:
1. 确保满足前提条件
在 安全数据湖 中配置HTTP API输入前,请确保:
-
目标REST API端点可从 安全数据湖 服务器访问。
-
API返回有效的JSON响应。
-
您已知晓待提取值的JSONPath。
-
若API需要认证,您已具备访问所需的凭据、令牌或请求头信息。
2. 在 安全数据湖
中配置输入 通过输入以下值进行配置:
|
字段 |
值 |
|---|---|
|
节点 |
选择启动此输入的节点。 |
|
标题 |
为您的输入提供一个唯一名称。 |
|
JSON资源的URI |
输入一个资源的URI,该资源在HTTP请求时返回JSON。 |
|
间隔 |
设置收集器运行之间的时间间隔。时间单位在下一个字段中设置。
示例:
如果您将
间隔
设置为
|
|
间隔时间单位 |
为收集器运行之间的间隔选择一个时间单位。 |
|
要提取数据的JSON路径 |
输入JSONPath表达式,指定要从JSON响应中提取的值。 更多信息,请参考 用例 . |
|
消息来源 |
指定在结果消息中用于源字段的值。 |
|
启用节流 |
允许 安全数据湖 在消息处理滞后时暂停此输入的数据摄入,使系统能够追赶进度。 |
|
HTTP方法(可选) |
选择请求的HTTP方法,默认为GET。 |
|
HTTP请求体(可选) |
输入HTTP请求体。若HTTP方法设置为POST或PUT,则此字段为必填项。 |
|
HTTP内容类型(可选) |
选择请求的HTTP内容类型。若HTTP方法为POST或PUT,则此字段为必填项。 |
|
额外的敏感HTTP头(可选) |
输入包含敏感信息(如授权凭证)的HTTP头,以逗号分隔。
示例:
|
|
额外HTTP头(可选) |
输入额外的HTTP头列表,以逗号分隔。
示例:
|
|
覆盖来源(可选) |
默认情况下,来源字段使用接收数据包中的主机名。您可以用自定义字符串覆盖此值,以便更好地识别或分类来源。 |
|
编码(可选) |
消息必须使用为输入配置的相同编码。例如,UTF-8消息不应发送到设置为UTF-16的输入。 |
|
扁平化JSON |
选择此选项以扁平化整个JSON。结果将作为消息字段返回: 来源 = github,json路径 = $.download_count,间隔时间单位 = 分钟 |
使用案例
以下示例从GitHub获取特定发布包的下载次数:
$ curl -XGET https://api.github.com/repos/YourAccount/YourRepo/releases/assets/12345
{
"url": "https://api.github.com/repos/YourAccount/YourRepo/releases/assets/12345",
"id": 12345,
"name": "somerelease.tgz",
"label": "somerelease.tgz",
"content_type": "application/octet-stream",
"state": "uploaded",
"size": 38179285,
"download_count": 9937,
"created_at": "2013-09-30T20:05:01Z",
"updated_at": "2013-09-30T20:05:46Z"
}
在此示例中,目标属性是
download_count
,因此JSONPath表达式设置为
$.download_count
.
提取的值会出现在 安全数据湖 中,显示为类似消息:
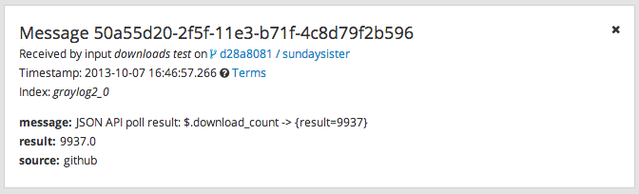
您现在可以使用 安全数据湖 来分析下载次数。
使用JSONPath
JSONPath的功能不仅限于选择单个字段。例如,您可以用它从发布列表中检索第一个
download_count
,其中
state
字段设置为
uploaded
:
$.releases[?(@.state == 'uploaded')][0].download_count
您可以选择列表中仅第一个
download_count
:
$.releases[0].download_count
有关JSONPath的更多信息,请参阅 此知识库文章 .
Microsoft Defender for Endpoint输入
Microsoft Defender for Endpoint是一种基于云的终端安全解决方案,通过资产管理、安全基线、漏洞评估和高级威胁防护等功能为企业设备提供保护。
配置Microsoft Defender for Endpoint输入需遵循以下步骤:
1. 确保满足先决条件
要使用Microsoft Defender for Endpoint插件,请在 您组织的Microsoft Azure门户中创建并授权客户端应用程序 . 安全数据湖 随后按设定间隔轮询Microsoft Defender for Endpoint并自动获取新日志。
2. 在Azure中进行必要配置
-
登录 Microsoft Azure .
-
从页面左侧菜单中选择 Microsoft Entra ID 。
-
在页面左侧菜单中依次选择 管理 > 应用注册 .
-
在页面右侧选择 新注册 。
-
按以下步骤注册新应用程序:
-
为应用程序命名(例如
安全数据湖日志访问. -
选择适当的账户类型:
单租户或多租户(根据您组织使用的是单个还是多个Active Directory实例)。 -
选择 注册 .
警告
不要添加重定向URI。
应用程序创建后,以下字段将自动生成:
-
应用程序(客户端) ID
-
目录(租户) ID
-
-
对于新创建的应用程序,请转到 证书和密码 .
-
选择 新建客户端密码 .
-
为新密码添加描述,选择过期时间,然后选择 添加 .
-
请记录应用程序(客户端) ID、目录(租户) ID和客户端密码。配置输入时需要这些值。
3. 在Azure中创建必要的客户端应用程序权限
-
对于新创建的应用程序,请转到 API权限 .
-
选择 添加权限 .
-
选择 我的组织使用的API .
-
搜索 WindowsDefenderATP .
-
选择 WindowsDefenderATP .
-
选择这些权限并点击 添加权限 :
-
Alert.Read.All -
Alert.ReadWrite.All -
User.Read.All -
Vulnerability.Read.All -
Machine.Read.All
-
-
选择 授予管理员同意...
-
选择 是 在弹出对话框中确认。
4. 在 安全数据湖
中配置输入
提示
您需要步骤2中的客户端ID、租户ID和客户端密钥值才能继续。
|
字段 |
值 |
|---|---|
|
输入名称 |
为输入输入一个唯一的名称。 |
|
目录(租户)ID |
安全数据湖 将收集日志数据的Active Directory实例的ID。 |
|
应用程序(客户端)ID |
步骤2中创建的客户端应用程序的ID。 |
|
客户端密钥值 |
这是在步骤2中生成的客户端密钥值。 |
|
轮询间隔 |
指定输入检查新日志数据的频率(以分钟为单位)。默认为5分钟,建议保持此值。该值不得小于1分钟。 |
|
启用限流 |
允许 安全数据湖 在消息处理滞后时暂停读取此输入的新数据,以便系统有时间追赶。 |
|
存储完整消息 |
允许
安全数据湖
将原始日志数据存储在每个消息的
|
Microsoft Graph输入
Microsoft Graph输入支持使用Microsoft Graph API收集电子邮件日志、Microsoft Entra ID日志、目录、配置和登录审计日志。有关 Microsoft Graph API .
1. 确保满足先决条件
确保满足以下先决条件:
-
您必须拥有现有的Entra ID账户。
-
必须为支持的日志类型定义具有以下权限的API用户:
日志类型
权限
许可证要求
电子邮件日志
User.ReadAll,User.ReadBasic.All,邮件.读取,邮件.基本读取,邮件.基本读取.全部,邮件.读取写入Microsoft Office 365 商业版
目录审核日志
审核日志.读取.全部,目录.读取.全部,目录.读取写入.全部登录审核日志
审核日志.读取.全部至少 Microsoft Entra P1 或 P2
预配审核日志
审核日志.读取.全部
2. 配置 Azure 应用
按照 微软官方指南 创建新的 Azure 应用并生成认证所需的凭据。在设置过程中,请记录 客户端 ID , 租户 ID 和 客户端密钥 。在配置 安全数据湖 .
3. 在 Security Data Lake 中配置输入
通过输入以下数值配置输入:
|
字段 |
数值 |
|---|---|
|
输入名称 |
为输入指定一个唯一名称。 |
|
租户 ID |
指定用于收集日志数据的 Microsoft Entra ID 账户的租户 ID。 |
|
客户端 ID |
输入在 Microsoft Entra ID 账户中注册的应用程序的客户端 ID。 |
|
客户端密钥 |
输入为在 Microsoft Entra ID 账户中注册的应用程序生成的客户端密钥。 |
|
订阅类型 |
选择您组织的 Azure AD 订阅类型。 |
|
收集的日志类型 |
选择要从 Microsoft Graph 收集的日志类型。默认选择所有日志类型,至少必须选择一种日志类型。 |
|
轮询间隔 |
指定输入检查 Microsoft Graph 中新数据的频率(分钟)。最小允许间隔为 5 分钟。 |
|
读取时间偏移(分钟) |
定义在尝试读取之前,输入等待新日志在 Microsoft Graph 中可用的时间长度。 |
|
启用节流 |
当消息处理滞后时,允许系统暂时暂停从此输入读取新数据,以便赶上处理进度。 |
Microsoft Office 365 输入
Microsoft Office 365 是一个广泛使用的基于云的生产力工具套件,允许您将组织的 Office 365 日志拉取到 Security Data Lake 进行处理、监控和告警。
注意
虽然微软已经 将其Office 365产品更名为Microsoft 365 ,但如下文档记录的输入内容不受此次变更影响。
1. 确保满足先决条件
请确保满足以下先决条件:
-
在组织的Microsoft Azure门户中创建并批准一个授权客户端应用程序,以启用Office 365插件。
-
拥有可访问审计日志和Microsoft Azure门户的有效Office 365订阅。
注意
具有E5或A5许可证的账户通常包含所需访问权限,但您应确认是否属实。
安全数据湖 会按设定时间间隔轮询Office 365审计日志并自动获取新日志。
3. 在Azure中配置应用
-
登录 Microsoft Azure .
-
选择 Azure Active Directory 从屏幕左侧菜单中。
-
从页面左侧菜单中选择 管理 > 应用注册 .
-
在页面右侧选择 新注册 。
-
通过以下步骤注册新应用程序:
-
为应用程序提供名称,例如
安全数据湖日志访问. -
选择适当的账户类型:
单租户或多租户,具体取决于您的组织使用一个还是多个Active Directory实例。 -
选择 注册 .
警告
不要添加重定向URI。
应用程序创建后,以下字段将自动生成:
-
应用程序(客户端) ID
-
目录(租户) ID
-
-
对于新创建的应用程序,请转到 证书和密码 .
-
选择 新建客户端密码 .
-
为新密码添加描述,选择过期时间,然后选择 添加 .
-
请记录应用程序(客户端) ID、目录(租户) ID和客户端密码。在配置输入时需要这些值。
4. 在Azure中创建必要的客户端应用程序权限
-
对于新创建的应用程序,请转到 API权限 .
-
选择 添加权限 .
-
选择 Office 365管理API .
-
选择 应用程序权限 .
-
选择列表中所有可用权限,然后选择 添加权限 .
-
选择 为...授予管理员同意
-
选择 是 在弹出对话框中确认。
启用统一审计记录
前往 审计日志搜索页面 在Microsoft Purview中并选择 开始记录用户和管理员活动 以启用审计记录。
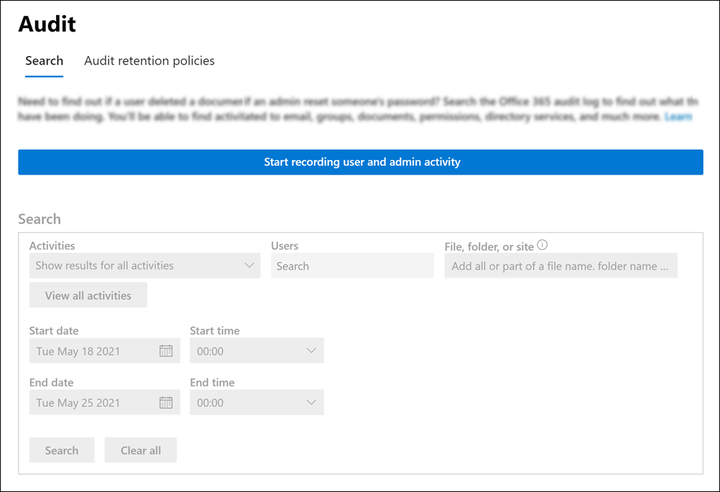
日志可能需要长达24小时才会出现在 安全数据湖 首次启用统一审计日志后。建议等待24小时后再开始 安全数据湖 中的Office 365输入设置,以确保Azure订阅已正确配置审计记录功能。
如果未显示标有“开始记录用户和管理员活动”的蓝色按钮,则表示审计记录已启用,可继续执行剩余配置步骤。
4. 在 安全数据湖
中配置输入
|
O365连接配置字段 |
值 |
|---|---|
|
输入名称 |
为Office 365输入配置一个独特的名称。 |
|
目录(租户)ID |
指定Active Directory实例的ID, 安全数据湖 将从此处收集日志数据。 |
|
应用程序(客户端)ID |
输入在Microsoft Azure门户中创建的客户端应用程序ID。 |
|
客户端密钥值 |
输入为注册应用程序生成的客户端密钥值。 |
|
订阅类型 |
选择您组织使用的Office 365订阅类型。 企业版 和 GCC政府计划 是最常见的选项。 |
O365内容订阅
|
字段 |
值 |
|---|---|
|
要收集的日志类型 |
指定输入从Office 365获取的五种可用日志类型。默认全选:Azure Active Directory、SharePoint、Exchange、常规和DLP。 |
|
轮询间隔 |
指定输入检查新日志数据的频率(以分钟为单位)。 默认间隔为5分钟(推荐值),且不得少于1分钟。 |
|
丢弃包含敏感数据的DLP日志 |
Office 365会为每个DLP事件生成摘要日志(不含敏感数据)和详细日志(含敏感数据)。启用此选项将丢弃详细日志,以防止敏感数据存储至 安全数据湖 . |
|
启用限流 |
允许 安全数据湖 在消息处理滞后时暂停读取此输入的新数据,为系统提供追赶时间。 |
|
存储完整消息 |
允许
安全数据湖
将原始日志数据存储在每个消息的
启用此选项会显著增加存储空间使用量。 |
Mimecast输入
Mimecast输入支持通过Mimecast API收集电子邮件安全日志,实现与 安全数据湖 的无缝集成,以增强电子邮件威胁分析和监控能力。该输入从Mimecast API 2.0版本拉取日志。
注意
本信息适用于Mimecast输入(v2.0 API)。Mimecast输入(v1.0 API)已弃用
1. 确保满足先决条件
请确保满足以下先决条件:
2. 在Mimecast中设置API应用程序
参考 Mimecast文档 获取创建和配置API应用程序的说明。
3. 在 安全数据湖
中配置输入
|
字段 |
值 |
|---|---|
|
输入名称 |
输入一个唯一的、用户定义的输入名称。 |
|
客户端ID |
输入与您的Mimecast API应用程序关联的客户端ID。 |
|
客户端密钥 |
输入为您的Mimecast API应用程序生成的客户端密钥。 |
|
需收集的日志类型 |
选择要收集的日志类型。默认情况下所有日志类型均被选中。至少需选择一种日志类型。 |
|
轮询间隔 |
指定从Mimecast API 安全数据湖 检查新数据的频率(以分钟为单位)。最小允许间隔为5分钟。 |
|
启用节流 |
允许 安全数据湖 在消息处理滞后时暂停从此输入读取新数据,为系统提供追赶时间。 |
NetFlow输入
NetFlow是思科开发的网络协议,提供用于监控和分析的IP流量数据。通过 安全数据湖 ,您可以收集包含源、目标、服务数据及其他相关数据点的IP流数据。对 NetFlow 导出的支持取决于设备。
在 安全数据湖
中配置NetFlow输入 启动新输入后 ,根据您的偏好配置以下字段:
-
全局
-
勾选此复选框可在所有 安全数据湖 节点上启用该输入,或保持未勾选以在特定节点上启用。
-
-
节点
-
选择 安全数据湖 此输入将关联的节点。
-
-
标题
-
为输入分配一个标题。 示例 :“XYZ源的NetFlow输入”。
-
-
绑定地址
-
输入此输入将监听的IP地址。源系统/数据将日志发送到此IP/输入。
-
-
端口 :
-
输入与IP配合使用的端口。默认端口2055是大多数设备的标准端口。但如果需要多个输入,需参考供应商文档了解其他端口选项(常见选项有9555、9995、9025和9026)。
-
-
接收缓冲区大小(可选)
-
此设置决定处理前存储传入数据的缓冲区大小。较大的缓冲区可容纳更多数据,减少高流量期间数据丢失的可能性。根据输入的数据流量大小,此值应足够大以确保数据正常流动,但又足够小以避免系统耗费资源处理缓冲数据。最佳大小取决于网络流量。 安全数据湖 的默认设置较为保守,测试和小规模部署时为256 KB。因此,如果处理大量NetFlow数据,建议增加此值。实际建议是从至少1 MB(1024 KB)的缓冲区大小开始,并根据观察到的性能进行调整。
-
-
工作线程数
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提高数据处理速度,从而提升吞吐量。配置的理想线程数取决于 安全数据湖 服务器上的可用CPU核心数。常见的起点是将工作线程数与CPU核心数对齐。但需注意与其他服务器需求保持平衡。
-
-
覆盖源(可选)
-
默认情况下,消息将源字段解析为日志消息中提供的主机名。但如果要覆盖输出非标准或不可配置主机名的设备的此设置,可在此处设置替代源名称。
-
-
编码(可选)
-
所有消息需支持为输入配置的编码。例如,UTF-8编码的消息不应发送到配置为支持UTF-16的输入。
-
-
NetFlow 9字段定义(可选)
-
NetFlow v9字段定义指定每种数据类型的解释方式。准确定义字段对确保正确解析和理解收集的NetFlow数据至关重要。应根据网络设备导出的特定数据类型自定义字段定义。
以下是定义NetFlow v9字段的示例.yml文件结构。此示例包含Juniper Networks EX系列交换机通常导出的字段。请注意,实际字段及其ID可能因交换机配置和NetFlow版本而异。请根据Juniper Networks EX系列交换机导出的特定NetFlow数据调整这些定义。
-
netflow_definitions:
# 基本流字段
- id: 1
name: IN_BYTES
type: UNSIGNED64
description: 与IP流关联的字节数的N×8位长度的入站计数器。
- id: 2
name: IN_PKTS
type: UNSIGNED64
description: 与IP流关联的数据包数的N×8位长度的入站计数器。
- id: 10
name: INPUT_SNMP
type: UNSIGNED32
description: 输入接口索引。使用此值查询SNMP IF-MIB。
- id: 14
name: OUT_BYTES
type: UNSIGNED64
description: 与IP流关联的字节数的N×8位长度的出站计数器。
- id: 15
name: OUT_PKTS
type: UNSIGNED64
description: 与IP流关联的数据包数的N×8位长度的出站计数器。
- id: 16
name: OUTPUT_SNMP
type: UNSIGNED32
description: 输出接口索引。使用此值查询SNMP IF-MIB。
设备采样率
下表包含基于平均流量大小的设备推荐采样率。
|
数据量(第95百分位) |
推荐采样率 |
|---|---|
|
< 25 Mb/s |
1:1 |
|
< 100 Mb/s |
1:128 |
|
< 400 Mb/s |
1:256 |
|
< 1 Gb/s |
1:512 |
|
< 5 Gb/s |
1:1024 |
|
< 25 Gb/s |
1:2048 |
Okta日志事件输入
Okta系统日志记录与组织相关的事件,并提供平台活动的审计追踪。此输入功能可获取 Okta日志事件对象 并将其摄入 安全数据湖 以便对组织活动进行进一步分析。
配置Microsoft Defender for Endpoint输入需遵循以下步骤:
1. 确保满足先决条件
请确保满足以下先决条件:
-
拥有具备管理权限的有效Okta组织账户。
-
已为Okta租户启用API访问权限。
-
从Okta管理控制台生成的API令牌,该令牌需具备读取系统日志事件的足够权限。
-
Okta系统日志API端点URL,通常格式为:
https://<your_okta_domain>/api/v1/logs
-
需确保从 安全数据湖 服务器到Okta API端点(443端口,HTTPS)的网络连通性。
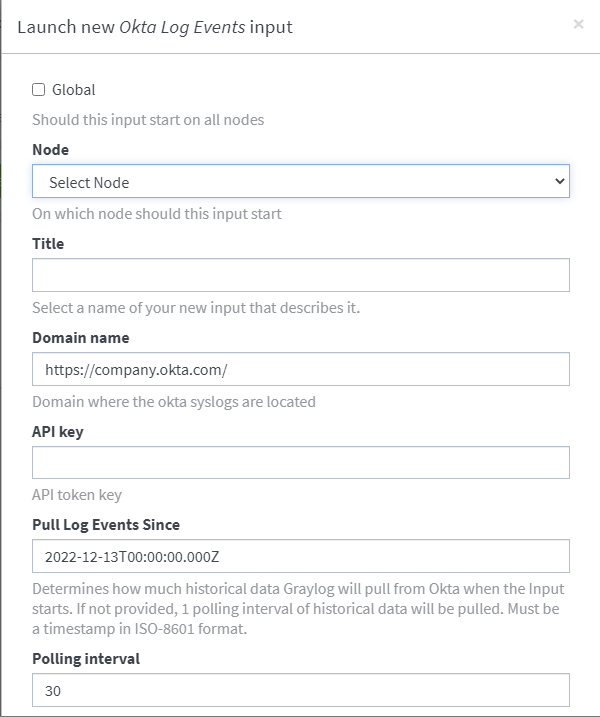
2. 在 安全数据湖
中配置输入
|
通过输入以下值配置输入: |
字段 |
|---|---|
|
值 |
域名 输入您的Okta域名(也称为Okta URL)。从Okta开发者控制台复制该域名。 更多信息请参阅 . |
|
。 |
API密钥 输入用于验证 安全数据湖 向Okta发起请求的API令牌。从Okta开发者控制台创建API令牌。 详情请参见 . |
|
。 |
拉取日志事件起始时间 指定要收集的Okta日志事件的最早时间。这决定了 安全数据湖 启动输入时拉取的历史数据量。 若未提供, 安全数据湖 |
|
将获取一个轮询间隔的历史数据。时间戳必须采用ISO-8601格式。 |
轮询间隔 定义 安全数据湖 |
|
向Okta轮询新日志数据的频率。该值不得小于5秒。 关键词过滤器(可选) |
根据指定关键词筛选日志事件结果。最多可使用10个以空格分隔的关键词,每个关键词最长40个字符。 |
OpenTelemetry (gRPC) 输入源
OpenTelemetry Google远程过程调用(gRPC)输入源支持 安全数据湖 通过gRPC上的OpenTelemetry协议(OTLP)接收来自经过OpenTelemetry插桩的应用和服务的日志数据。
通过使用此输入源,您可以接收结构化的OpenTelemetry日志,将相关字段映射到 安全数据湖 的内部模式,并对其遥测数据应用搜索、分析和告警功能。
先决条件
在继续之前,请确保满足以下先决条件:
-
安装 OpenTelemetry收集器 .
-
要将OpenTelemetry日志发送到 安全数据湖 ,需要将 安全数据湖 服务器配置为日志的后端。以下配置片段提供了将OpenTelemetry收集器配置为向 安全数据湖 发送日志的示例;但它们 并不 代表收集器的完整配置。
-
不安全的、未经认证的日志导出。
警告
此配置不安全, 不推荐用于生产环境 。仅用于测试!
导出器: otlp/graylog: 端点: "graylog.test:4317" tls: 不安全: true 服务: 管道: 日志: 导出器: [debug, otlp/graylog] -
TLS,Bearer令牌认证
扩展: bearertokenauth/withscheme: 方案: "Bearer" 令牌: "kst40ngmpq22oqej9ugughgh48i81n0vbm0tbuqnqk0oop5jl0h" 导出器: otlp/graylog: 端点: "graylog.test:4317" 认证: 认证器: bearertokenauth/withscheme tls: ca文件: /tls/rootCA.pem 服务: 扩展: [bearertokenauth/withscheme] 管道: 日志: 导出器: [debug, otlp/graylog] -
TLS,无认证
导出器: otlp/graylog: 端点: "graylog.test:4317" tls: ca文件: /tls/rootCA.pem 服务: 管道: 日志: 导出器: [debug, otlp/graylog] -
双向TLS
导出器: otlp/graylog: 端点: "graylog.test:4317" tls: ca文件: /tls/rootCA.pem 证书文件: /tls/client.pem 密钥文件: /tls/client-key.pem 服务: 管道: 日志: 导出器: [debug, otlp/graylog]
-
传输层安全性 (TLS)
为确保通信安全,OpenTelemetry (gRPC) 输入提供多种认证和加密机制,可单独使用或组合使用以增强安全性。OpenTelemetry (gRPC) 输入在安全配置上具有灵活性,可实现以下功能:
-
仅使用TLS,数据加密但不强制客户端认证。
-
启用mTLS,确保只有持有有效证书的可信客户端能连接。
-
使用承载令牌认证作为mTLS的替代方案,要求客户端通过令牌认证。
安全数据湖 输入配置
从 安全数据湖 输入 选项卡启动此输入时,需配置以下字段值:
-
节点 :节点设置决定输入应在特定 安全数据湖 节点上运行还是全局适用于所有节点。勾选 全局 复选框可在所有节点上运行输入。
-
标题:为输入分配标题以便识别。
-
绑定地址 :输入此输入监听的IP地址。源系统/数据将日志发送至该IP地址/输入。
-
端口 :默认情况下,输入监听0.0.0.0(所有网络接口)并使用4317端口,与OpenTelemetry基于gRPC的日志采集默认设置一致。
-
gRPC入站消息最大大小:消息的最大尺寸。默认值4194304字节(约4MB)通常足够,但可根据消息长度调整。
-
允许节流(复选框):若启用,当 安全数据湖 内部处理队列达到上限时,输入将暂时停止读取新消息。节流可防止内存过载并确保系统稳定性,尤其在高吞吐场景下。为避免日志数据丢失,应实施适当的重试机制。OpenTelemetry SDK和收集器通常支持对瞬时故障的重试,但需确认其配置符合预期的退避和重试策略。
-
必填承载令牌(可选):除TLS外或作为替代认证方式,该输入支持承载令牌认证。当定义必填承载令牌时,所有客户端必须在请求的授权标头中包含此令牌。此方法无需客户端证书即可实现访问控制。
-
允许不安全连接(复选框):禁用TLS加密以允许与服务器建立不安全连接。
注意
后续TLS相关设置确保有效源能安全地向输入发送消息。
-
TLS服务器证书链(可选): 可启用TLS加密以保护传输中的日志数据。激活TLS需提供TLS服务器证书链,其中包含用于验证输入的PEM编码证书。
-
TLS服务器私钥(可选): 此方法为支持加密通信所必需。若证书由受信任的证书颁发机构(CA)签发,客户端无需额外配置即可建立安全连接。
-
TLS客户端证书链(可选): 为增强认证,可通过指定TLS客户端证书链启用双向TLS(mTLS)。此方法确保仅持有可信机构签发有效证书的客户端能向 安全数据湖 发送日志。若配置mTLS,输入将拒绝未授权客户端的连接。
-
覆盖源(可选): 默认源为从接收数据包派生的主机名。您可用自定义字符串覆盖默认值。此选项允许根据特定需求优化源。
将OpenTelemetry日志字段映射至 安全数据湖 字段
日志接收后, 安全数据湖 将关键OpenTelemetry日志字段映射至其内部模式以实现高效索引与查询。由于 安全数据湖 不支持消息中的嵌套字段,根据OpenTelemetry Protobuf规范传入的日志信号结构无法精确映射到 安全数据湖 日志消息。将OpenTelemetry日志映射为 安全数据湖 消息时,会应用若干规则。
注意
通常, 安全数据湖 会自动将传入消息字段名中的点号(.)替换为下划线(_)。
以下部分重点说明OpenTelemetry日志消息如何转换为 安全数据湖 消息。
核心 安全数据湖 消息字段映射
这些字段展示了核心 安全数据湖 消息字段如何从传入的OpenTelemetry日志记录中映射而来。
-
source: 发起输入连接的远程对端地址。
-
timestamp: 优先使用OpenTelemetry日志中的time_unix_nano字段,若存在;否则使用observed_time_unix_nano,或回退到输入处记录接收的时间戳。
-
message: OpenTelemetry日志记录body字段的内容。
一级字段映射
|
OpenTelemetry字段 |
安全数据湖 字段 |
|---|---|
|
|
otel_trace_id |
|
|
otel_span_id |
|
|
otel_trace_flags |
|
|
|
|
|
otel_severity_number |
|
|
otel_time_unix_nano |
|
observed_time_unix_nano |
otel_observed_time_unix_nano |
资源与属性映射
-
资源属性: 以otel_resource_attributes_为前缀并转换为 安全数据湖 字段。
-
资源模式URL: 映射为otel_resource_schema_url。
-
日志属性: 以otel_attributes_为前缀。
-
日志模式URL: 映射为otel_schema_url。
-
检测范围:
-
otel_scope_name -
otel_scope_version -
otel_scope_attributes_*
-
值处理
-
基本类型 (字符串、布尔值、整数、双精度浮点数):直接转换。
-
字节 :Base64编码。
-
列表 :
-
单一类型基本值:转换为列表。
-
混合基本值:转换为字符串列表。
-
嵌套数组/映射:序列化为JSON。
-
-
映射 :展平为独立字段,使用_作为分隔符。
注意事项与限制
虽然此输入支持 安全数据湖 对OpenTelemetry的支持时,需注意以下几点重要事项。首先,仅支持日志数据。通过OTLP/gRPC传输的指标和追踪数据不会被此输入接收。此外,不支持HTTP协议的OTLP;该输入仅接受通过gRPC传输的数据。若您运行的 安全数据湖 位于负载均衡器后方,必须确保开放所需端口并正确转发TLS/mTLS配置,以维持安全且不间断的通信。
Palo Alto网络输入
Palo Alto网络输入允许
安全数据湖
直接接收来自Palo Alto设备及Palo Alto Panorama系统的
系统
,
威胁
和
流量
日志。设备端采用标准Syslog输出。日志以典型syslog标头开头,后接逗号分隔的字段列表。字段顺序可能随
PAN-OS
.
示例
系统
消息:
<14>1 2018-09-19T11:50:35-05:00 Panorama-1 - - - - 1,2018/09/19 11:50:35,000710000506,SYSTEM,general,0,2018/09/19 11:50:35,,general,,0,0,general,informational,"异常设备:Prod--2, 序列号:007255000045717, 对象:N/A, 指标:mp-cpu, 值:34",1163103,0x0,0,0,0,0,,Panorama-1
开始使用时,请在 系统 > 输入 中添加新的Palo Alto网络输入(TCP)。指定 安全数据湖 节点、绑定地址、端口,并根据需要调整字段映射。
警告
应配置Palo Alto设备以 非自定义格式 .
安全数据湖 包含三种不同的输入类型:
-
Palo Alto Networks TCP (PAN-OS v8.x)
-
Palo Alto Networks TCP (PAN-OS v9+)
-
Palo Alto Networks TCP (PAN-OS v11+)
警告
根据Palo Alto Networks官网说明,PAN-OS 8.1*、9.0和10.0版本已终止支持。8.1版本可能仍会提供关键修复。详情请参阅 Palo Alto官方文档 。
PAN-OS 8输入配置
注意
在
输入
表单中配置时区前,请注意默认值为
UTC+00:00-UTC
。但您可以通过输入配置表单的下拉菜单设置为特定偏移量。由于PAN设备日志不包含时区偏移信息,此字段可确保
安全数据湖
正确解析日志时间戳。若PAN设备设置为
UTC
,则无需更改此值。
该输入预装了与
PAN OS 8.1
兼容的字段配置。其他版本需通过自定义
SYSTEM
,
THREAT
及
TRAFFIC
映射来支持,相关设置在
安全数据湖
.
每种消息类型的配置为一个CSV块,必须包含
位置
,
字段
和
类型
表头。
例如:
1,receive_time,STRING 2,serial_number,STRING 3,type,STRING 4,content_threat_type,STRING 5,future_use1,STRING ...
|
字段 |
可接受值 |
|---|---|
|
|
一个正整数。 |
|
|
用于字段名的连续字符串值。不得包含保留字段名:
|
|
|
以下支持的其中一种类型:
|
当Palo Alto输入启动时,会检查每个CSV配置的有效性。如果CSV格式错误或包含无效属性,输入将无法启动。错误信息会显示在 系统 > 概览 页面顶部。
例如:

插件内置的默认映射基于以下PAN-OS 8.1规范。如果运行的是PAN-OS 8.1,则无需编辑映射。但如果运行其他版本的PAN-OS,请参考Palo Alto Networks官方日志字段文档,并在 添加/编辑输入 页面上进行相应自定义映射。
PAN-OS 9输入
PAN-OS 9输入会自动检测摄取的数据是否来自9.0或9.1版本。9.1版本自动支持且开箱即用。
我们在此提供几个近期版本的链接供参考。
版本9.1
另请参阅 旧版PAN OS版本文档
PAN-OS 11 输入
PAN-OS 11输入会自动检测摄取的数据是否来自11.0或更高版本,并使用处理管道或Illuminate内容处理日志数据。此输入不会完全解析整个消息架构,而是提取关键字段,如
event_source_product
和
vendor_subtype
,这些字段会被添加到消息中。
我们在此提供了几个近期版本的链接以供参考。
版本11.0
随机HTTP消息生成器
随机HTTP消息生成器输入是一个 安全数据湖 实用工具,旨在为测试、基准测试或演示目的生成模拟的HTTP消息流量。它不依赖外部数据源,而是以可配置的间隔自主生成类似HTTP的消息,并将其发送到 安全数据湖 的处理管道中。这在测试流规则、提取器、管道和仪表板时特别有用,无需依赖实时日志源。
此输入在选定的 安全数据湖 节点上本地运行(如果配置为全局,则跨所有节点运行),并通过在消息时间和源信息中引入随机变化来模拟真实、非稳定的消息流。
要求与准备
由于消息是由 安全数据湖 内部生成的,因此不需要外部系统向此输入发送消息。但在启用之前,应满足以下条件:
-
节点可用性 - 确保选择承载输入的节点(服务器、转发器或边车)处于活动状态并正确连接到集群。
-
系统资源 - 根据配置的休眠间隔和偏差,持续生成消息可能产生高负载。请确保有足够的CPU和内存资源。
-
目标环境 - 此输入主要适用于测试或预发布环境,而非生产环境,因为它会生成模拟数据并可能干扰正常消息处理统计。
-
目标配置 - 确保 安全数据湖 的管道、流或提取器已设置为正确处理或丢弃这些测试消息。
在 安全数据湖
中创建随机HTTP消息生成器输入时,需配置以下字段:
|
字段 |
描述 |
|---|---|
|
节点 |
指定此输入启动的节点。可用于将消息生成定向到特定转发器或SDL集群组件。 |
|
标题 |
输入的自定义名称,便于在其他输入中快速识别。例如:“测试HTTP生成器 - SDL集群”。 |
|
休眠时间 |
定义两个生成消息之间的基准延迟(毫秒)。数值越低,消息吞吐量越高。 |
|
最大随机休眠时间偏差 |
在基准休眠时间上增加随机延迟(最大为本值毫秒数),以模拟不规则消息流。例如:基准休眠25毫秒加30毫秒偏差时,每条消息延迟将在25至55毫秒之间。 |
|
源名称 |
指定生成消息中用作“来源”字段的主机名或标识符。可以是任意名称,如
|
|
允许限制此输入 |
启用后,若处理管道滞后,输入将自动暂停消息生成,确保 安全数据湖 不会过载。通常在需要全吞吐量的合成测试中保持禁用状态。 |
|
覆盖来源(可选) |
允许手动覆盖从接收数据包派生的默认主机名。若希望所有生成消息显示为来自特定主机,此功能非常有用。 |
|
编码(可选) |
设置生成消息的字符编码。默认为
|
使用说明
-
性能测试 - 调整休眠时间和最大随机偏差以模拟不同的消息摄取速率和突发模式。
-
流验证 - 可使用生成的消息验证 安全数据湖 的流规则、提取器或管道处理逻辑。
-
隔离 - 为便于调试期间清晰区分,设置唯一来源名称以便在搜索界面轻松过滤这些消息。
-
清理 - 由于此输入生成非必要数据,测试后请记得停止或删除它,防止污染消息索引。
原始HTTP输入
原始HTTP输入支持接收纯文本HTTP请求。此输入可用于通过 安全数据湖 的HTTP协议接收任意日志格式消息。
注意
此输入监听
/raw
路径上的HTTP POST请求。
安全数据湖 配置
当从 安全数据湖 输入 选项卡中,需填写以下配置参数:
-
全局
-
勾选此复选框可在所有 安全数据湖 节点上启用此输入,或保持未勾选状态以在特定节点上启用输入。
-
-
节点
-
选择要启动此输入的节点。若已选择 全局 复选框,则此选项不可用。
-
-
标题
-
为输入提供唯一名称。
-
-
绑定地址
-
输入此输入监听的IP地址。源系统/数据通过此IP地址将日志发送至该输入。
-
-
端口
-
输入与IP地址配合使用的端口。
-
-
接收缓冲区大小 ( 可选 )
-
此设置决定处理前存储传入数据的缓冲区大小。较大的缓冲区可容纳更多数据,降低高流量期间数据丢失的概率。根据输入的数据流量,该值应足够大以确保数据正常流动,同时足够小以避免系统耗费资源处理缓冲数据。最佳大小取决于网络流量规模。 安全数据湖 的默认设置为保守的256 KB,适用于测试和小规模部署。若需处理大量NetFlow数据,建议增大此值。实用建议是从至少1 MB(1024 KB)的缓冲区开始,并根据实际性能调整。
-
-
工作线程数 ( 可选 )
-
此设置控制用于处理传入数据的并发线程数。增加线程数可提升数据处理速度,从而提高吞吐量。理想线程数取决于 安全数据湖 服务器的可用CPU核心数。通常建议将工作线程数与CPU核心数对齐,但需与其他服务器需求保持平衡。
注意
以下TLS相关设置确保有效来源能够安全地向输入端发送消息。
-
-
TLS证书文件 ( 可选 )
-
存储在 安全数据湖 系统上的证书文件。该字段的值为一个路径(
/路径/到/文件), 安全数据湖 必须能够访问权限。
-
-
TLS私钥文件 ( 可选 )
-
存储在 安全数据湖 系统上的证书私钥文件。该字段的值为一个路径(
/路径/到/文件), 安全数据湖 必须能够访问权限。
-
-
启用TLS
-
若该输入端需使用TLS,请勾选此项。
-
-
TLS密钥密码 ( 可选 )
-
私钥密码。
-
-
TLS客户端认证 ( 可选 )
-
若要求向此输入发送消息的源进行身份验证,请设置为可选或必需。
-
-
TLS客户端认证受信任证书 ( 可选 )
-
客户端(源)证书在 安全数据湖 系统上的存放路径。该字段值为一个路径(
/path/to/file), 安全数据湖 必须有权访问。
-
-
TCP保活
-
启用此选项可使输入支持TCP保活数据包以防止空闲连接。
-
-
启用批量接收
-
启用此选项以接收由换行符(
\n或\r\n).
-
-
启用CORS
-
启用跨源资源共享(CORS)以配置服务器在HTTP响应中发送特定头部,指示浏览器允许跨源请求。
-
-
最大HTTP分块大小 ( 可选 )
-
对于大数据,通常采用分块处理较小数据块(如8KB或64KB分块)以防止缓冲区过载。最大HTTP分块大小为65536字节。
-
-
写入器超时时间 ( 可选 )
-
服务器在因无活动而关闭连接前,等待客户端向输出流发送数据的最大时间。
-
-
授权头名称 ( 可选 )
-
指定自定义授权头名称,可选择对所有接收消息强制认证。此设置是为该输入添加类密码安全的一种方式。
-
-
授权头值 ( 可选 )
-
指定授权头值,可选择对所有接收消息强制认证。
-
-
覆盖来源 ( 可选 )
-
默认情况下,消息将来源字段解析为日志消息中提供的主机名。但若需为输出非标准或不可配置主机名的设备覆盖此设置,可在此处设置替代来源名称。
-
-
编码 ( 可选 )
-
所有消息需支持输入配置的编码。默认编码为UTF-8。例如,不应将UTF-8编码消息发送至配置为支持UTF-16的输入。
-
启动Raw HTTP输入后,可使用以下端点发送消息:
http://graylog.example.org:[端口]/raw (POST)
尝试使用curl发送示例消息:
curl -XPOST http://graylog.example.org:12202/raw -d '示例消息'
通过Raw HTTP输入实现Cloudflare Logpush
来自Cloudflare Logpush服务(通过HTTP目的地)的日志可以通过 安全数据湖 的Raw HTTP输入进行摄取。配置完成后,Logpush将通过HTTP协议向该输入发送以换行符分隔的日志消息批次。
关于此输入的一般信息(包括配置选项)可在 Raw HTTP输入 文档中查阅。
注意
您还可以在 使用Raw HTTP输入实现GitLab审计事件流 .
先决条件
在继续之前,请确保满足以下先决条件:
-
需要Cloudflare订阅。
-
Cloudflare Logpush HTTP目的地服务必须能够转发到您环境中受TLS保护的端点。详情请参阅 使用TLS保护输入 。(您也可以选择通过防火墙或网关路由以满足TLS要求)。
-
我们强烈建议在设置Raw HTTP输入时启用 授权标头 选项,以确保消息请求经过身份验证。
设置输入
转到 系统 > 输入 并选择 Raw HTTP 以启动新输入。为Cloudflare Logpush设置此输入时,必须仔细考虑以下配置设置:
-
绑定地址与端口 :确保Cloudflare能通过您的网络路由至指定的IP地址和端口。请注意,原始HTTP输入会在
/raw根HTTP路径监听请求。 -
TLS设置 :必须为此端点启用TLS,或选择通过防火墙/网关路由以满足TLS使用要求。
-
启用批量接收 :务必勾选此选项,以确保输入能正确分割Cloudflare发送的换行符分隔的日志批次。
-
授权请求头 :指定授权头的名称和值,确保输入仅接受通过认证的通信。
-
授权请求头名称 :
authorization -
授权请求头值 :选择符合长度与复杂度要求的安全密码,并在Cloudflare中使用相同值进行授权设置。
-
其他可用配置详见 原始HTTP输入 文档。除非环境有特殊需求,建议保持默认设置。
在Cloudflare中启用HTTP目标
设置新输入后,需启用Logpush服务将日志发送至 安全数据湖 。具体操作是将 安全数据湖 端点设为Logpush目标,流程说明参见 Cloudflare文档 .
注意
请注意, Cloudflare文档中描述的前几步 会引导您选择要与Logpush配合使用的网站(即域名)。可通过选择 网站 从Cloudflare管理控制台导航栏中选择 添加域名 。此步骤对于将Cloudflare日志导入 安全数据湖 !.
当系统提示输入原始HTTP输入监听请求的URI时,请确保URL包含
/raw
根路径。例如:
https://graylog-host:port/raw?header_Authorization=<Graylog输入授权头值>
通过原始HTTP输入实现GitLab审计事件流
来自 GitLab审计事件流 (通过HTTP目的地)的日志可被摄取至 安全数据湖 使用原始HTTP输入。配置成功后,GitLab将通过HTTP向输入发送以换行符分隔的日志消息批次。
关于此输入的一般信息(包括配置选项)可在 原始HTTP输入 文档中找到。
注意
请注意,您可以在 使用原始HTTP输入的Cloudflare日志推送
先决条件
继续之前,请确保满足以下先决条件:
-
需要拥有现有的GitLab账户。
-
必须配置一个 安全数据湖 原始HTTP输入 以监听可接受来自公网GitLab服务流量的端口。
设置GitLab审计事件流
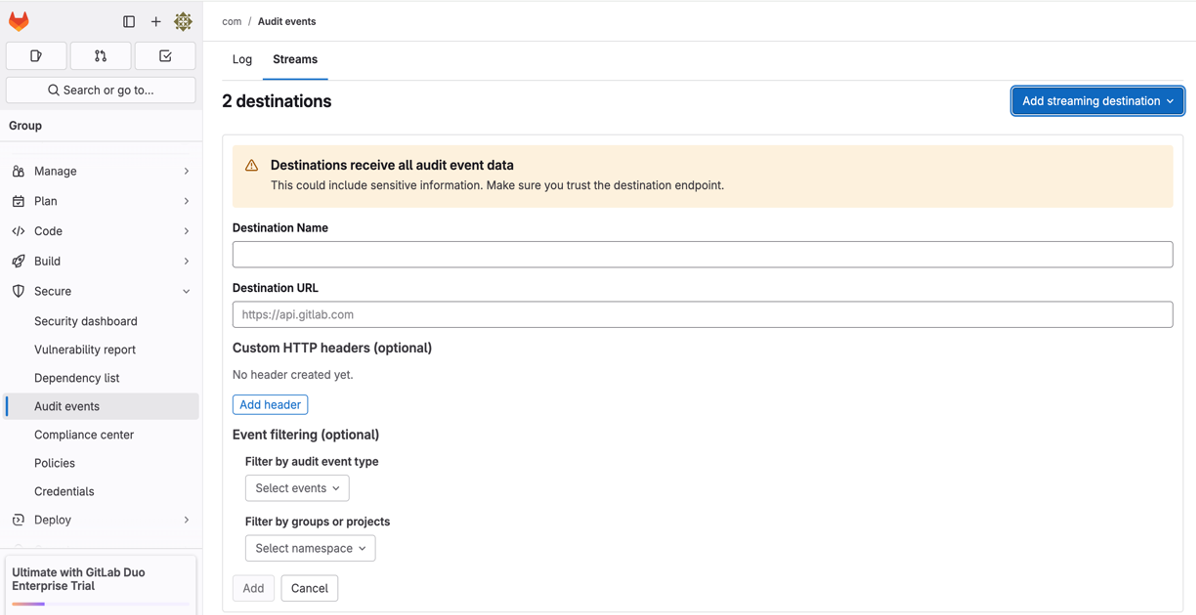
要将GitLab审计日志流式传输至 安全数据湖 ,需完成若干关键配置步骤。本节概述了将GitLab审计事件流与 安全数据湖 实例集成的必要设置。首先配置GitLab转发审计事件,随后在 安全数据湖 中指定目标详细信息,包括目标名称、服务器URL和自定义HTTP标头。此外,还可实现可选的事件过滤功能以定制捕获的审计日志。更多信息请参阅 GitLab官方文档 。
配置目标
-
目标 名称 :指定合适的目标名称。
-
目标 URL :指定运行原始HTTP输入的 安全数据湖 服务器的对外主机名和端口,例如
https://<数据洞察-服务器主机名>/raw.
-
自定义 HTTP 标头 :添加与上述输入配置中相同值的自定义标头。根据特定网络设置需求添加其他标头。
-
(可选) 事件 过滤 :确定要流式传输至的日志筛选条件 安全数据湖 输入。
设置输入
导航至 系统 > 输入 并选择 原始HTTP 以启动新输入。为GitLab审计事件流设置此输入时,必须仔细考虑以下配置项:
-
绑定地址与端口 :确保GitLab能通过您的网络路由到指定IP地址和端口。请注意原始HTTP输入会在
/raw根HTTP路径监听请求。 -
授权请求头 :指定授权头的名称和值。这将确保输入仅接受通过身份验证的通信。请输入上一节配置GitLab审计流服务时使用的相同值。
-
TLS设置 :必须为此端点启用TLS,或选择通过防火墙/网关路由以满足TLS使用要求。
-
启用批量接收 :务必勾选此选项。这将确保输入能正确分割GitLab发送的换行符分隔的日志消息批次。
其他可用配置项请参阅 原始HTTP输入 文档。除非环境有特殊需求,建议对额外配置属性使用默认设置。
Salesforce输入
Salesforce提供基于云的商业管理、客户关系管理和销售工具。该平台生成的多类日志可通过 安全数据湖 的 EventLogFile API 采集。更多信息请参考Salesforce官方文档中关于 所有支持的日志事件类型 .
Security Data Lake 目前支持所有EventLogFile的源类型,截止到版本58的 Salesforce EventLogFile API .
1. 确保满足先决条件
请确保满足以下先决条件:
-
包含 Salesforce事件监控附加组件 的Salesforce订阅,这是获取应用仪表板中所有数据所必需的。
2. 为EventLogFile API访问设置Salesforce
在 Security Data Lake 中配置输入之前,请先在Salesforce中完成以下步骤以启用EventLogFile API访问:
-
在Salesforce应用程序管理器中创建一个连接应用程序。有关详细说明,请参阅 Salesforce文档 .
-
在连接应用程序设置过程中,为 Security Data Lake 应用授予EventLogFile API的读取权限。
-
配置 连接应用的OAuth设置 。此步骤将生成Security Data Lake连接Salesforce API所需的客户端ID和客户端密钥。有关详细信息,请参阅 Salesforce文档 。 .
3. 在 Security Data Lake
配置输入,输入以下值:
|
字段 |
值 |
|---|---|
|
输入名称 |
为Salesforce输入输入一个唯一的名称。 |
|
Salesforce基础URL |
输入您的Salesforce实例的完整基础URL,例如:
|
|
消费者密钥 |
输入具有所需API权限的Salesforce Connected App中的消费者密钥。 |
|
消费者密钥 |
输入Salesforce Connected App中的消费者密钥。 |
|
要收集的日志类型 |
选择要收集的活动日志类型。输入将获取所选内容类型的日志。 |
|
轮询间隔 |
指定 安全数据湖 检查Salesforce中新数据的频率(以分钟为单位)。最小允许间隔为5分钟。 |
|
启用节流 |
允许 安全数据湖 在消息处理落后时暂停读取此输入的新数据,以便系统有时间赶上。 此设置适用于从文件或消息队列系统(如AMQP或Kafka)读取的输入。对于定期轮询外部系统(例如通过HTTP)的输入,建议保持此选项禁用。 |
Sophos Central输入
Sophos Central输入从Sophos Central的 SIEM集成API 收集事件和警报,以便在 安全数据湖 .
1. 确保满足先决条件
确保满足以下先决条件:
-
拥有 Sophos Central 订阅。
2. 配置Sophos以实现API访问
在Sophos Central中完成以下步骤以启用SIEM集成API访问:
-
按照官方 Sophos API凭证管理 文档生成API认证凭证。
-
创建凭证时,请选择 服务主体只读权限 以授予SIEM集成日志所需的访问权限。
-
凭证生成后,复制客户端ID和密钥ID。在配置 安全数据湖 .
3. 在 安全数据湖
中配置输入
|
字段 |
值 |
|---|---|
|
输入名称 |
为Sophos Central输入输入唯一名称。 |
|
客户端ID |
输入 客户端ID (在Sophos API凭证设置期间提供)。 |
|
客户端密钥 |
输入 客户端密钥 (在Sophos API凭证设置期间提供)。 |
|
接收警报 |
此输入自动接收Sophos事件。选择此选项可同时接收Sophos警报。 更多详情,请参阅 Sophos文档 . |
|
轮询间隔 |
指定输入检查新日志的频率(以分钟为单位)。最小允许间隔为5分钟。 |
|
启用节流 |
允许 安全数据湖 在消息处理滞后时暂停读取此输入的新数据,使系统有时间追赶进度。 |
重要提示
Sophos SIEM集成API仅保留24小时的日志数据。建议避免长时间停止此输入,以防因该限制导致日志出现缺口。
Symantec EDR事件输入
Symantec端点检测与响应(EDR)用于检测环境中的可疑活动并采取适当措施。EDR会收集各类事件及 事件类型 .
先决条件
-
您的Symantec订阅需包含 Symantec端点安全完整版 .
在EDR中完成设置
-
为使 安全数据湖 连接至Symantec EDR API,需创建一个具有足够权限的OAuth客户端,生成用于连接API的客户端ID和密钥。创建OAuth客户端的说明详见Symantec文档《 生成OAuth客户端 ."
-
必须指定一个包含以下权限的自定义角色:
atp_view_events,atp_view_incidents,atp_view_audit,以及atp_view_datafeeds.
在 安全数据湖
中配置输入
-
要启动新的SymantecEDR事件输入: 导航至 .
-
。 从输入选项中选择 Symantec EDR事件 ,然后点击 启动新输入
-
按钮。
按照设置向导配置输入。
-
配置参数
-
为您的输入提供一个唯一名称。
-
-
管理服务器主机
-
Symantec EDR管理服务器的IP地址或主机名。
-
-
客户端ID
-
具有足够API权限的Symantec EDR连接应用的客户端ID。
-
-
客户端密钥
-
Symantec EDR连接应用的客户端密钥。
-
-
要收集的日志类型
-
要获取的活动日志类型。
-
-
轮询间隔
-
轮询频率(分钟) 安全数据湖 检查Symantec EDR中新数据的时间间隔。最小允许间隔为5分钟。
-
-
启用限流
-
若启用,在 安全数据湖 处理完当前消息负载前,该输入将停止读取新消息。此配置参数通常适用于从文件或AMQP、Kafka等消息队列系统读取的输入。若通过HTTP等方式定期轮询外部系统,应保持此选项禁用。
-
支持的日志类型
安全数据湖 支持多种事件类型ID和事件。有关Symantec事件检测类型及描述的完整列表,请查阅 事件检测类型与描述文档。
Symantec SES事件输入
Symantec Endpoint Security (SES) 是Symantec Endpoint Protection (SEP) 的全云托管版本,提供多层防护以抵御全攻击向量的威胁。SES会生成多种类型的事件和 事件日志 ,可被收集并分析至 安全数据湖 .
1. 确保满足前提条件
请确保满足以下前提条件:
-
您的Symantec订阅需包含 Symantec Endpoint Security Complete .
2. 配置Symantec SES的API访问权限
在Symantec Endpoint Security (SES) 中完成以下步骤以允许访问事件流API:
-
在Symantec SES中创建事件流和客户端应用程序。
-
配置客户端应用程序时,需分配事件和告警的读取权限,使 安全数据湖 能从事件流API收集数据。
3. 创建客户端应用程序
按以下步骤在Symantec Endpoint Security (SES) 中创建客户端应用程序:
-
记录为该应用生成的客户端ID和OAuth令牌。在配置 安全数据湖 .
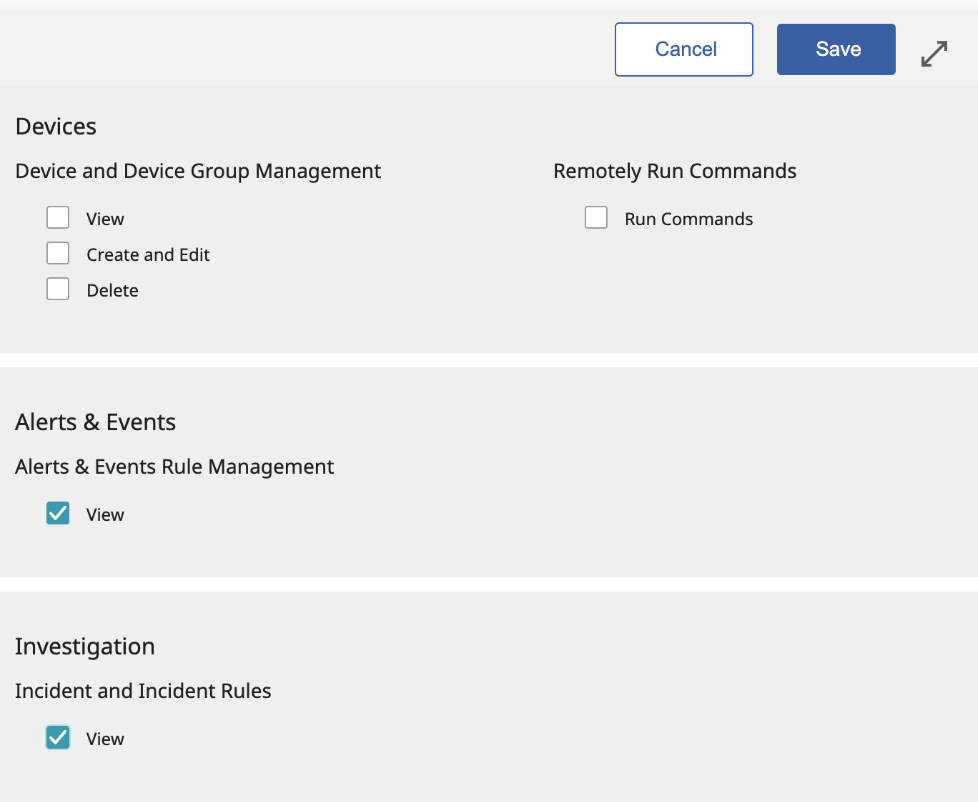
-
为该客户端应用程序指定 查看 权限,适用于
警报与事件及调查. -
为客户端应用程序分配权限:设置 查看 权限,适用于 警报与事件 和 调查 .
4. 创建事件流
按照以下步骤在Symantec Endpoint Security (SES)中创建事件流:
-
打开Symantec SES控制台。
-
新建一个 事件流 .
-
选择您希望 安全数据湖 在配置事件流时接收的所有事件类型。
-
记录 流GUID 和 通道 值。在 安全数据湖 .
5. 在 安全数据湖
中配置输入 通过输入以下值来配置输入:
|
字段 |
值 |
|---|---|
|
输入名称 |
为Symantec SES输入输入一个唯一的名称。 |
|
OAuth凭据 |
输入具有足够API权限的Symantec SES客户端应用程序的OAuth令牌。 |
|
托管位置 |
选择您的Symantec SES实例托管的区域。 |
|
要收集的日志类型 |
选择 安全数据湖 应从Symantec SES获取的活动日志类型。 |
|
流GUID |
输入为数据流创建的包含所需事件类型的事件流的GUID。 |
|
通道数量 |
指定为事件流配置的通道数量。 |
|
轮询间隔 |
定义 安全数据湖 从Symantec SES检查新数据的频率(以分钟为单位)。最小间隔为5分钟。 |
|
启用节流 |
允许 安全数据湖 当消息处理滞后时暂停读取此输入的新数据,以便系统有时间追赶进度。 此选项主要适用于从文件或消息队列系统(如AMQP或Kafka)读取的输入。对于轮询外部系统(例如通过HTTP)的输入,建议保持此选项禁用。 |
|
检查点间隔 |
指定记录检查点的频率(以秒为单位) 安全数据湖 为Symantec SES数据流记录检查点。 |
|
流连接超时 |
定义事件流连接超时时间(以分钟为单位)。该值决定流连接保持活动状态的时长。 |
支持的日志类型
安全数据湖 支持多种事件类型ID和事件。有关Symantec事件检测类型及描述的完整列表,请查阅 事件检测类型及描述 .