流水线
流水线是 安全数据湖 日志消息处理系统的核心组件,为评估、修改和路由传入数据提供结构化框架。它们定义了消息摄取后所应用的处理步骤序列,确保日志数据得到一致、高效且定制化的处理。
每条流水线由一系列 规则 组成,并归类到 数据流 中,可关联一个或多个数据流。这种连接方式让您能精确控制特定消息的处理方式和时机,实现对数据增强、标准化及路由的细粒度管理。
提取器
提取器 是 安全数据湖 最初用于在日志消息被摄取时进行处理和解析。建议改用管道(pipelines),这是一种更健壮且可定制化的集中式消息处理方法。管道具有灵活性,支持条件逻辑,并能跨多个输入源运行。
核心概念
管道
管道是由按阶段组织的管道规则集合构成的。当附加到数据流时,进入该流的消息会按照预定义的阶段顺序通过所有连接的管道进行处理。
管道规则
管道规则定义了决定消息处理方式的逻辑。
它们可以:
-
将消息路由到不同数据流
-
通过添加或修改字段来丰富数据
-
转换消息内容
-
标准化消息格式以实现一致的搜索和分析
一组协同运作的关联规则构成了完整的管道工作流。
函数
函数 是管道规则的基本构建单元。每个函数执行特定操作(如解析文本、检查字段值或更改消息内容),并可接受参数来控制其行为。 函数返回的结果会影响后续规则对消息的处理方式。
阶段
管道分为多个阶段,每个阶段包含一条或多条规则。阶段按数字顺序依次执行。
所有具有相同优先级的阶段会在所有连接的管道中并行执行。这种结构支持构建多步骤工作流,例如:在一个阶段解析消息,在另一个阶段丰富数据,最后在最终阶段进行路由。
数据流
每个管道必须附加到至少一个 数据流 ,这决定了管道处理哪些消息。
进入数据流的消息会触发所有连接管道的执行。更多信息请参阅数据流文档。
管道规则逻辑
安全数据湖中的 管道 由管道规则构建,这些规则定义了日志消息在被索引或存储前如何被检查、转换和路由。这些规则使用专用的领域特定语言(DSL),该语言提供了可控且可读的语法来定义处理逻辑,同时保持强大的运行时性能。
每条规则都包含一个条件和一个 动作 :
-
条件决定规则何时适用。
-
动作则规定条件满足时执行的操作。
编写规则时必须理解数据类型。数据类型定义了字段所持有的值类型(如字符串、数字或IP地址),以及该值在规则中如何被操作。
流水线规则通过函数构建——这些预定义方法执行特定任务,如转换数据类型、操作字符串、解析JSON或获取 查找表 数据。 安全数据湖 包含大量内置函数,可有效帮助您丰富、转换和管理日志数据。
规则可通过 规则构建器 界面交互式创建和测试,或由高级用户在源代码编辑器中手动编写。
示例流水线
以下示例展示流水线及其规则在内部的结构:
流水线 "我的新流水线" 阶段1 全匹配 规则 "包含防火墙字段"; 规则 "来自防火墙子网"; 阶段2 任一匹配 规则 "IP地理编码"; 规则 "匿名化源IP"; 结束
该流水线定义了两个阶段:
-
阶段1仅当所有列出的规则评估为真时执行。
-
阶段2在其任意规则匹配时执行(类似于OR条件)。
阶段按数字升序运行,每个阶段可引用可重用规则。这种模块化设计使得诸如
包含防火墙字段
的规则能在多个流水线中共享,避免重复。
示例规则
以下是上述流水线中引用的两条示例规则:
规则1
规则 "包含防火墙字段"
当
存在字段("src_ip") && 存在字段("dst_ip")
则
结束
规则2
规则 "来自防火墙子网"
当
cidr_match("10.10.10.0/24", 转IP($消息.gl2_远程_ip))
则
结束
两条规则均使用内置函数定义条件:
-
存在字段()用于检查特定消息字段是否存在。 -
cidr_match()用于评估IP地址是否属于定义的子网范围。
通过
to_ip()
转换确保值被解析为IP地址而非字符串,这体现了
安全数据湖
在规则验证时严格的类型强制机制。
这些规则不包含动作(
then
为空),因为它们仅用于控制管道流。
条件
规则的
when
子句是针对每条消息评估的布尔表达式。
它支持逻辑运算符AND(
&&
)、OR(
||
)和NOT(
!
),以及比较运算符如
<
,
<=
,
>
,
>=
,
==
,以及
!=
.
例如:
has_field("src_ip") && cidr_match("10.0.0.0/8", to_ip($message.src_ip))
若条件引用了不存在的函数,则自动判定为
false
.
比较字段时需确保类型一致,例如:
to_string($message.src_ip) == to_string($message.dst_ip)
动作
当条件判定为
then
时,该子句定义将执行的操作
true
.
动作可以是:
-
函数调用,如
set_field("type","firewall_log"); -
变量赋值,如
letsubnet=to_string($message.network);
变量可用于存储临时值、避免重复计算并提升规则可读性。
保留字
规则语言中的特定标记为保留字,不可作为变量名,包括:
-
All -
Either -
Pass -
And -
Or -
Not -
管道 -
规则 -
在...期间 -
阶段 -
当 -
那么 -
结束 -
令 -
匹配
例如:
let match = regex(a,b);
将失败,因为match是保留字。
数据类型
安全数据湖 在管道规则中强制类型安全以防止无效操作。支持以下内置数据类型:
|
数据类型 |
描述 |
|---|---|
|
字符串 |
UTF-8文本值 |
|
双精度浮点数 |
浮点数(Java Double) |
|
长整型 |
整数(Java Long) |
|
布尔型 |
真或假值 |
|
空 |
无返回值的函数 |
|
IP地址 |
IP地址(InetAddress的子集) |
插件可定义其他类型。以...为前缀的转换函数
转换为_
(例如,
to_string()
,
to_ip()
,
to_long()
)以确保正确的类型处理。完整函数列表请参阅
函数参考
.
注意
在使用消息字段进行比较或函数操作前,务必将其转换为正确类型。 例如:
set_field("timestamp", to_string(`$message.@extracted_timestamp`));
构建流水线规则
流水线通过规则定义消息在流经 安全数据湖 时的处理方式。每条规则通过条件与动作的组合,允许您基于特定标准对日志数据进行过滤、丰富、转换或路由。
创建规则时,您可使用规则构建器或源代码编辑器定义其逻辑,将“当”条件与“则”动作结合,精确描述消息处理方式。规则创建后,可被添加至流水线中,分阶段组织并关联到数据流——从而实现从数据摄入到存储的灵活自动化消息处理控制。
本文概述创建和管理流水线规则的流程。
配置消息处理器
开始构建流水线规则前,请确保 消息处理器 已启用并正确配置:
-
转到 系统 > 配置 .
-
选择 消息处理器 .
-
选择 编辑配置 并启用 流水线处理器 勾选其旁边的复选框。
-
拖动 流水线处理器 使其位于 消息过滤链 之后。使用左侧的六个点进行拖动。
-
点击 更新配置 .
创建和管理规则
规则可通过 规则构建器 或 源代码编辑器 .
规则构建器(默认视图)提供了一种引导式的可视化规则创建方式。
如需切换至手动编辑,请从创建菜单中选择 使用源代码编辑器 。
警告
您可以将规则从规则构建器转换至源代码编辑器,但不可逆向转换。
使用规则构建器创建规则
规则构建器提供了一种可视化、结构化的方法,可直接在 安全数据湖 界面中编写规则。
每条规则都遵循简单的“当→则”模式:
-
当 用于定义触发规则的条件。
-
则 用于定义满足条件时执行的操作。
两个输入框均支持可搜索的下拉菜单。输入函数名的前几个字母即可显示建议项和简短描述。完整函数列表请参阅《函数文档》。
使用规则构建器创建规则的步骤如下:
-
前往 系统 > 管道 > 管理规则 .
-
选择 创建规则 .
-
创建when条件语句。
-
(可选)可添加其他语句,并通过 与 或 运算符进行组合 运算符,可从页面右上角区域选择 当 部分。
-
创建一个 然后 语句指定操作。
若then语句生成值,输出变量将自动显示并可在后续语句中复用。
注意
规则可立即在 规则模拟 模块中测试。
使用源代码编辑器创建规则
也可通过 源代码编辑器 手动编写when/then语句规则。该视图支持完整语法编辑,并包含函数速查表及其说明。
使用源代码编辑器创建规则需遵循以下步骤:
-
前往 系统 > 管道 > 管理规则 .
-
选择 创建规则 .
-
选择 使用源代码编辑器 从页面右上角选择。
-
配置规则。
注意
有关语法详情,请参阅 流水线规则逻辑 。
-
选择 创建规则 .
与规则构建器类似,您可以在保存前于规则模拟模块验证规则。
模拟流水线规则
模拟功能允许您在部署前测试规则。可模拟完整消息或单个字段。在模拟框中输入原始消息字符串、键值对或JSON载荷。
模拟器会逐步显示分配的输出变量和处理结果。
提示
最近使用的消息会随每条规则保存,便于随时调用模拟。
运行模拟的步骤如下:
-
前往 系统 > 流水线 > 模拟器 .
-
选择运行规则模拟。
-
输入示例消息。
-
查看处理后的输出。
-
如需可重置或调整规则并重新运行。
管理流水线
创建规则后,可将其组合成处理和丰富消息的流水线。前往 系统 > 管道 > 管理管道 以创建、编辑或删除管道。
每个管道包含一个或多个定义执行顺序和逻辑的阶段。
创建管道
要创建新管道,请按照以下步骤操作:
-
转到 系统 > 管道 > 管理管道 .
-
选择 添加新管道 按钮位于屏幕右上角。
-
为管道输入描述性名称和说明,并选择???
-
选择 编辑连接 在 管道连接 部分下。
将显示 编辑连接 窗口。
-
在 流 字段下,选择要附加的流。
注意
管道仅作用于其所连接流中的消息。多个管道可处理同一流;其规则按阶段优先级执行。
提示
“ 所有消息 ”流是所有传入数据的默认入口点,也是处理路由、过滤或字段丰富化的通用管道的理想位置。
选中后,它们将被添加到菜单下方的列表中。您可以选择 移除 将其从列表中删除。
-
选择 添加新阶段 并配置该阶段:
-
在 阶段 下输入阶段优先级,该数值决定管道在序列中的执行顺序。此数字可为任意整数,数值较小的阶段将优先执行。
-
选择如何处理后续阶段的规则:
-
本阶段所有规则均匹配消息 - 仅当满足所有条件时继续下一阶段。
-
本阶段至少有一条规则匹配消息 - 满足任一条件即继续下一阶段
-
本阶段无规则匹配或匹配多条规则 - 仅当未满足任何条件时继续下一阶段。
-
-
在阶段规则下,选择要应用的规则。
-
选择 添加阶段 以保存信息。
-
-
如需,可添加更多阶段。
注意
每个新建阶段都会在 管道 菜单。选择 编辑 以修改阶段详情,或 删除 以移除该阶段。
添加所有阶段后,流水线即告完成,将显示在流水线页面。连接到数据流后,它将根据您定义的规则和逻辑自动开始处理传入消息。
数据流测试与流水线模拟
使用流水线模拟器预览消息如何通过当前流水线设置进行处理。测试数据流步骤如下:
-
前往 系统 > 流水线 > 模拟器 .
-
在 数据流 下,选择要测试的数据流。
-
在 原始消息 下,提供与传入日志格式相同的原始样本消息(例如GELF格式消息)。
-
(可选)指定源IP、输入类型和编解码器(日志消息的解析机制)。
执行后,模拟器将显示:
-
变更摘要 ——列出被修改、添加或删除的字段。
-
结果预览 ——展示完整处理后的消息。
-
模拟追踪 ——详细说明执行的规则和流水线及其耗时。
编辑与流水线阶段
所有流水线均显示在 系统 > 流水线 > 管理流水线 页面下。针对每条流水线,您可以选择 删除 移除该流水线,或选择 编辑 修改其配置。
使用场景
本文介绍在 安全数据湖 中创建和应用流水线规则的实际用例。这些示例展示了如何过滤无效日志、丰富消息数据,并将消息路由至特定流或告警系统。您可参考这些场景来设计并实施高效的流水线规则,从而优化日志数据的处理与分析流程。
|
规则 |
条件示例 |
执行示例 |
规则语法 |
|---|---|---|---|
|
匿名化处理 流水线规则可在消息存储或转发前对敏感数据进行编辑或删除。 通过掩码IP地址、用户名或个人标识符等信息,确保符合隐私标准。 |
检查是否存在
|
从消息中删除
|
规则 "掩码敏感信息"
当
存在字段("source_ip")
则
移除单字段("source_ip");
结束
|
|
追踪标记 面包屑规则会为消息添加元数据,以便追踪其在系统或处理阶段间的流转路径。 这类规则常用于调试、打标签或跟踪消息处理过程。 |
留空。这将确保规则适用于所有传入消息。 |
添加或更新字段
|
规则 "设置演示字段"
当
true
则
设置字段("rule_demo", "test");
结束
|
|
过滤 过滤规则可帮助丢弃非必要消息,从而减少数据摄入量和许可证使用。 |
检查
|
完全丢弃该消息,避免其被存储或进一步处理。 |
规则 "丢弃测试消息"
当
存在字段("testing")
则
丢弃消息();
结束
|
|
修改 修改规则会变更消息内容,例如重新格式化时间戳或更新字段值。 |
检查消息是否包含
|
将时间戳从UTC转换为英国时间,并写入名为
|
规则 "将event_time转换为英国时区"
当
存在字段("event_time")
则
令 event_time_date = 解析日期(
值: 转字符串($消息.event_time),
格式: "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", // 根据需要调整此格式
时区: "UTC"
);
令 event_time_uk = 格式化日期(
值: event_time_date,
日期格式: "yyyy-MM-dd'T'HH:mm:ss.SSSZ",
时区: "Europe/London"
);
设置字段("event_time_uk", event_time_uk
);
结束
|
|
enrichment 富化规则通过添加额外上下文或更新现有数据值来增强消息。 |
检查字段
|
将该字段值更新为
|
规则 "SrcCountryUnitedStates"
当
存在字段("Src_ip_geo_country") &&
转字符串($消息.Src_ip_geo_country) == "US"
则
设置字段(
字段: "Src_ip_geo_country",
值: "UniSt",
清除字段: 否
);
结束
|
|
路由 路由规则将特定消息发送至另一流,并可选地从当前流中移除。 提示在规则中引用目标流前,请预先创建该目标流。 |
检查
|
将消息路由至目标流(
|
规则 "路由消息至流"
当
存在字段("gl2_remote_ip") &&
转字符串($消息.gl2_remote_ip) == "66914166ac1d1568bad817f3"
则
路由至流(
名称: "我的首个流",
从默认流移除: 是
);
结束
|
流水线函数
函数是流水线规则的构建模块。每个函数都是预定义方法,在日志消息流经 安全数据湖 处理流水线时对其执行特定操作。
函数可接受一个或多个参数,并返回决定消息如何转换、丰富或路由的输出结果。通过在条件和动作中组合函数,您可定义强大的处理逻辑,使消息处理符合组织需求。
完整支持的 安全数据湖 函数列表、描述及语法示例,请参阅 函数参考 .
语法
安全数据湖 中的流水线函数 采用Java实现并设计为可插拔式,便于扩展平台处理能力。
从概念上讲,函数接收参数(如当前消息上下文)并返回值。参数和返回数据类型决定了函数在规则中的使用场景。 安全数据湖 会自动验证这些类型,以确保所有规则在逻辑和语法上都是合理的。
函数参数可以按命名键值对传递,也可以按位置顺序传递,前提是任何可选参数都需声明并在最后处理。
Java数据类型
流水线规则在构建查询或执行计算时可以使用某些Java数据类型。这仅限于通过
GET
函数查询的类型。
例如,您可以使用
.millis
属性(属于
DateTime
和
Period
对象用于以毫秒为单位获取时间值。
这使您能够执行精确的时间计算,例如测量消息相对于当前时间的存在时长。
规则 "时间差计算器(毫秒)"
当
条件为真
则
定义时间差 =
转换为长整型(
解析日期(
值: 转换为字符串(当前时间(时区: "欧洲/柏林")),
格式: "yyyy-MM-dd'T'HH:mm:ss.SSSZ",
区域: "de_DE"
).毫秒数
)
-
转换为长整型(
解析日期(
值: 转换为字符串($消息.时间戳),
格式: "yyyy-MM-dd'T'HH:mm:ss.SSSZ",
区域: "de_DE"
).毫秒数
);
设置字段("扫描时间差_毫秒", 时间差);
结束
本示例中,规则计算了当前时间("欧洲/柏林"时区)与消息时间戳之间的毫秒级差值。
计算结果(
scan_age_millis
)表示事件的存活时长(毫秒),并作为新字段存入消息。
警告
安全数据湖 不支持使用任何未官方文档记载的函数。若测试未支持函数数据类型,请谨慎操作。
函数类型
内置 安全数据湖 函数可按以下类型分类。完整函数列表及说明参见 函数参考手册 .
匿名化
匿名化函数用于混淆数据集或日志消息中的敏感数据。
资产增强
资产增强函数用于改进、检索或移除资产相关日志数据。详见 资产增强 章节了解该 安全数据湖 安全特性的详细信息。
布尔值
布尔数据主要与条件语句相关联,通过根据条件评估结果为
真
或
假
来改变控制流以实现不同的操作。布尔函数用于确定布尔值或运算符。
转换
转换函数用于将值从一种格式转换为另一种格式。
日期/时间
日期/时间函数用于对日期和时间值执行操作或计算。
调试
调试函数用于确定程序在任意执行点的状态。
编码
编码函数可用于解码和转换字符串。
列表
列表函数可创建或检索用于分析操作的数据集合。
查找
查找函数支持在数据库中检索特定值并返回同记录的其他信息。
映射
映射函数对集合中的每个或所有元素应用指定操作。
消息处理
消息处理函数定义如何响应消息。在构建管道规则时,它们用于日志数据的各种丰富、移除、检索和路由操作。
模式匹配
模式匹配函数用于指定数据应遵循的模式,并根据这些模式解构数据。
字符串
字符串函数用于操作字符串或查询字符串相关信息。
监视列表
监视列表函数提供检索或修改监视列表的操作功能。
函数参考
以下列表描述了 安全数据湖 .
|
函数 |
类别 |
描述 |
语法 |
|---|---|---|---|
|
缩写 |
字符串 |
使用省略号缩写字符串。宽度参数定义结果字符串的最大长度。 |
|
|
abusech_ransom_lookup_domain |
字符串 |
根据abuse.ch勒索软件域名黑名单(RW_DOMBL)匹配域名
|
|
|
abusech_ransom_lookup_ip |
字符串 |
将IPv4或IPv6地址与abuse.ch勒索软件域名黑名单进行匹配
|
|
|
add_asset_categories |
资产丰富化 |
为资产添加类别列表。 |
|
|
anonymize_ip |
匿名化 |
通过将最后一个八位组设置为
|
|
|
array_contains |
消息处理 |
检查数组中是否包含指定元素。 参见示例 |
|
|
array_remove |
消息处理 |
从数组中移除指定元素。 参见示例 |
|
|
base16_decode |
字符串 |
提供返回小写字母的字符串base16解码。需要常规十六进制字符,0-9 A-F。 |
|
|
base16_encode |
字符串 |
提供使用16字符子集的标准不区分大小写十六进制编码。要求常规十六进制字符,0-9 A-F。 |
|
|
base32_decode |
字符串 |
使用32字符子集解码字符串。采用"数字型"base32编码,从传统十六进制字母扩展而来,0-9 A-V。 |
|
|
base32_encode |
字符串 |
使用32字符子集编码字符串。采用"数字型"base32编码,从传统十六进制字母扩展而来,0-9 A-V。 |
|
|
base32human_decode |
字符串 |
使用32字符子集以人类可读格式解码字符串。此为"易读型"base32编码,避免0/O或1/I混淆,采用A-Z 2-7字符集。 |
|
|
base32human_encode |
字符串 |
使用32字符子集以人类可读格式编码字符串。此为"易读型"base32编码,避免0/O或1/I混淆,采用A-Z 2-7字符集。 |
|
|
base64_decode |
字符串 |
使用64字符子集解码字符串。标准base64允许大小写字母,无需人类可读性。 |
|
|
base64_encode |
字符串 |
使用64字符子集编码字符串。标准base64允许大小写字母,无需人类可读性。 |
|
|
base64url_decode |
字符串 |
使用64字符子集对字符串进行URL安全解码。适合用作文件名或直接传入URL而无需转义。 |
|
|
base64url_encode |
字符串 |
使用64字符子集对字符串进行URL安全编码。适合用作文件名或直接传入URL而无需转义。 |
|
|
首字母大写 |
字符串 |
将字符串首字母转为标题格式(大写)。 |
|
|
cidr匹配 |
布尔值/消息函数 |
检查给定IP地址对象是否匹配CIDR模式。 另请参阅: to_ip |
|
|
克隆消息 |
消息处理 |
克隆消息。若
|
|
|
连接 |
字符串 |
返回合并
参见示例 |
|
|
contains |
字符串 |
检查字符串是否包含另一字符串,忽略大小写。 参见示例 |
|
|
crc32 |
字符串函数/编码 |
返回给定字符串的十六进制编码CRC32摘要。 |
|
|
crc32c |
字符串函数/编码 |
返回给定字符串的十六进制编码CRC32C(RFC 3720第12.1节)摘要。 |
|
|
create_message |
消息处理 |
根据给定参数创建新消息。若省略任一参数,其值将从当前处理消息的对应字段中获取。若
|
|
|
csv_to_map |
转换 |
将单行CSV字符串转换为可供
另请参阅: set_fields |
|
|
days |
日期/时间 |
创建一个时间周期,包含
|
|
|
debug |
调试 |
将传入的值以字符串形式打印到 安全数据湖 日志中。注意调试信息仅会出现在处理您试图调试消息的 安全数据湖 节点日志中。 参见示例 |
|
|
drop_message |
消息处理 |
移除指定的
参见示例 |
|
|
ends_with |
String |
检查
参见示例 |
|
|
expand_syslog_priority |
转换 |
将 syslog优先级数值 转换为其对应的级别和设施。 |
|
|
expand_syslog_priority_as_string |
转换 |
将 syslog优先级数值 转换为其严重性和设施字符串表示形式。 |
|
|
first_non_null |
列表 |
返回指定列表中第一个非
|
|
|
flatten_json |
字符串 |
解析
|
|
|
flex_parse_date |
日期/时间 |
使用
Natty日期解析器
解析日期和时间
另请参阅: is_date |
|
|
format_date |
日期/时间 |
返回给定的日期和时间
|
|
|
from_forwarder_input |
消息处理 |
检查当前处理的消息是否通过指定转发器输入接收。可通过输入
|
|
|
from_input |
消息处理 |
检查当前处理的消息是否通过指定(非转发器)输入接收。可通过输入
|
|
|
get_field |
消息处理 |
获取字段的
|
|
|
grok |
模式匹配 |
应用grok模式
另请参阅: set_fields |
|
|
grok_exists |
布尔值 |
检查给定Grok模式是否存在。
|
|
|
has_field |
布尔值/消息函数 |
检查给定
|
|
|
小时 |
日期/时间 |
创建一个时间周期,包含
|
|
|
in_private_net |
消息处理 |
检查一个IP地址是否位于RFC 1918(10.0.0.0/8、172.16.0.0/12、192.168.0.0/16)或RFC 4193(fc00::/7)定义的私有网络中。 |
|
|
is_bool |
布尔值 |
检查给定的
|
|
|
is_collection |
布尔值 |
检查给定的
|
|
|
is_date |
布尔值 |
检查给定的
另请参阅: now , parse_date , flex_parse_date , parse_unix_milliseconds |
|
|
is_double |
布尔值 |
检查给定的
另请参阅: to_double |
|
|
is_ip |
布尔值 |
检查给定的
另请参阅: to_ip |
|
|
is_json |
布尔值 |
检查给定
另请参阅: parse_json |
|
|
is_list |
布尔值 |
检查
|
|
|
is_long |
布尔值 |
检查
另请参阅: to_long |
|
|
is_map |
布尔值 |
检查给定的
另请参阅: to_map |
|
|
is_not_null |
布尔型 |
检查
参见示例 |
|
|
is_null |
布尔型 |
检查
参见示例 |
|
|
is_number |
布尔型 |
检查给定的
|
|
|
is_period |
布尔值 |
检查给定的
|
|
|
is_string |
布尔值 |
检查
另请参阅: to_string |
|
|
is_url |
布尔值 |
检查给定
另请参阅: to_url |
|
|
join |
字符串 |
将指定范围内的数组元素连接为单个字符串。起始索引默认为
|
|
|
key_value |
Boolean |
从给定的
还需注意,执行
另请参阅: set_fields |
|
|
length |
String |
计算字符串中的字符数。若bytes=true,则改为计算字节数(假定为UTF-8编码)。 |
|
|
list_count |
List |
获取列表中元素的数量。 |
|
|
list_get |
列表 |
从列表中获取值。 |
|
|
lookup |
查找 |
在命名的查找表中查询多值。 参见示例 |
|
|
lookup_add_string_list |
查找 |
在命名的查找表中添加字符串列表,成功时返回更新后的列表,失败时返回
|
|
|
lookup_all |
查找 |
在命名的查找表中查询所有提供的值,并将所有结果以数组形式返回。 参见示例 |
|
|
lookup_assign_ttl |
查找 |
为命名的查找表中的键添加生存时间。成功时返回更新后的条目,失败时返回
|
|
|
lookup_clear_key |
查找 |
清除(移除)指定查找表中的键。 此函数目前仅支持 MongoDB查找表 (截至撰写时)。 |
|
|
lookup_has_value |
查找 |
判断指定
|
|
|
lookup_remove_string_list |
查找 |
从指定查找表中移除给定字符串列表的条目。成功时返回更新后的列表,失败时返回
|
|
|
lookup_set_string_list |
查找 |
在指定查找表中设置字符串列表。成功时返回新值,失败时返回
|
|
|
lookup_set_value |
查找 |
在指定查找表中设置单个值。成功时返回新值,
|
|
|
lookup_string_list |
查找 |
在指定查找表中查找字符串列表值。 此函数目前仅支持 MongoDB查找表 (截至撰写时)。 |
|
|
lookup_string_list_contains |
布尔值 |
查找
|
|
|
lookup_value |
Lookup |
查找单个
参见示例 |
|
|
lowercase |
String |
将
|
|
|
machine_asset_lookup |
资产丰富 |
查找单个机器资产。如果多个资产匹配输入参数,则仅返回其中一个。 |
|
|
machine_asset_update |
资产丰富 |
更新机器资产的IP或MAC地址。如果多个资产匹配输入参数,则仅选择其中一个。 |
|
|
map_copy |
Map |
从映射中检索值。 |
|
|
map_get |
Map |
将映射复制到新映射。 |
|
|
map_remove |
映射 |
从映射中移除键。 |
|
|
map_set |
映射 |
设置映射中的键。 |
|
|
md5 |
字符串 |
生成值的十六进制编码MD5摘要
|
|
|
metric_counter_inc |
调试 |
统计特定指标条件。计数器指标
|
|
|
millis |
日期/时间 |
创建具有
|
|
|
minutes |
日期/时间 |
创建一个时间周期,包含
|
|
|
months |
日期/时间 |
创建一个时间周期,包含
|
|
|
multi_grok |
对字符串应用一组Grok模式并返回首个匹配项。 查看示例 |
|
|
|
murmur3_128 |
编码 |
生成指定
|
|
|
murmur3_32 |
编码 |
生成指定
|
|
|
normalize_fields |
消息处理 |
将所有字段名转换为小写形式以实现标准化。 |
|
|
now |
日期/时间 |
返回当前
另请参阅: is_date |
|
|
otx_lookup_domain |
字符串 |
查询指定域名的AlienVault OTX威胁情报数据。需要配置名为
参见示例 |
|
|
otx_lookup_ip |
字符串 |
查询IPv4或IPv6地址的AlienVault OTX威胁情报数据。需要配置名为
参见示例 |
|
|
parse_cef |
字符串 |
将CEF格式的字符串解析为对应字段。该CEF字符串(以
|
|
|
parse_date |
日期/时间 |
使用指定日期格式解析日期字符串。 |
|
|
parse_json |
字符串 |
将
另请参阅: to_map |
|
|
parse_unix_milliseconds |
日期/时间 |
尝试将UNIX毫秒时间戳(自1970-01-01T00:00:00.000Z起的毫秒数)解析为正确的
另请参阅: is_date 参见示例 |
|
|
period |
日期/时间 |
从
另请参阅: is_period , years , months , weeks , days , hours , minutes , seconds , 毫秒 |
|
|
正则表达式 |
模式匹配 |
使用Java语法将字符串与正则表达式进行匹配。 |
|
|
正则替换 |
模式匹配 |
将正则表达式模式与值进行匹配,若匹配成功则替换为
参见示例 |
|
|
移除资产分类 |
资产增强 |
从资产中移除分类列表。 |
|
|
移除字段 (已弃用) |
消息处理 |
从指定
|
|
|
remove_from_stream |
消息处理 |
从指定流中移除
如需彻底丢弃消息,请使用
|
|
|
remove_multiple_fields |
消息处理 |
移除符合正则表达式(regex)模式和/或名称列表的字段,除非字段名是保留字段。 |
|
|
remove_single_field |
消息处理 |
从消息中移除单个字段,除非字段名是保留字段。 |
|
|
rename_field |
消息处理 |
修改字段名称
|
|
|
replace |
字符串 |
替换字符串中的前
参见示例 |
|
|
route_to_stream |
消息处理 |
将消息的流分配设置为指定流。功能类似于“复制”,不会从当前流中移除消息。若
参见示例 |
|
|
秒 |
日期/时间 |
创建一个时长为
|
|
|
select_jsonpath |
映射 |
对给定的
另请参阅: is_json , parse_json |
|
|
set_associated_assets |
资产丰富化 |
添加关联资产信息。 |
|
|
set_field |
消息处理 |
将指定
另请参阅: set_fields |
|
|
set_fields |
消息处理 |
在给定消息中设置所有指定的名称-值对到
|
|
|
sha1 |
编码 |
创建该值的十六进制编码SHA1摘要
|
|
|
sha256 |
编码 |
创建该值的十六进制编码SHA256摘要
|
|
|
sha512 |
编码 |
创建该值的十六进制编码SHA512摘要
|
|
|
spamhaus_lookup_ip |
查询 |
将IP地址与Spamhaus DROP和EDROP列表进行匹配。 |
|
|
split |
字符串 |
根据此模式匹配拆分字符串。使用Java语法。 |
|
|
starts_with |
字符串 |
检查
参见示例 |
|
|
string_array_add |
字符串 |
将指定字符串(或字符串数组)
参见示例 |
|
|
string_entropy |
字符串 |
计算给定字符串中字符分布的香农熵。 |
|
|
substring |
字符串 |
返回
参见示例 |
|
|
swapcase |
字符串 |
交换
|
|
|
syslog_facility |
转换 |
将
系统日志设施编号
中的
|
|
|
syslog_level |
转换 |
将
系统日志严重性编号
中的
|
|
|
threat_intel_lookup_domain |
查询 |
将域名与所有启用的威胁情报源(OTX除外)进行匹配。 |
|
|
threat_intel_lookup_ip |
查询 |
将IP地址与所有启用的威胁情报源(OTX除外)进行匹配。 |
|
|
to_bool |
转换 |
根据参数的字符串值将其转换为布尔值。 |
|
|
to_date |
转换 |
将
另请参阅: is_date |
|
|
to_double |
转换 |
将第一个参数转换为双精度浮点数值。 |
|
|
to_ip |
转换 |
将给定的
另请参阅: cidr_match |
|
|
to_long |
转换 |
将第一个参数转换为长整数值。 |
|
|
to_map |
转换 |
将给定的类映射值转换为有效映射。
另请参阅: set_fields , parse_json 参见示例 |
|
|
to_string |
转换 |
将第一个参数转换为其字符串表示形式。 |
|
|
to_url |
转换 |
将给定的
|
|
|
tor_lookup |
查询 |
将IP地址与已知Tor出口节点匹配,以识别来自Tor网络的连接。 |
|
|
traffic_accounting_size |
消息处理 |
计算整个消息的大小,包括所有额外字段。该值也用于确定消息对许可证使用量的贡献程度。 参见示例 |
|
|
uncapitalize |
字符串 |
将字符串首字母转换为小写。 |
|
|
uppercase |
字符串 |
将字符串转换为大写。区域设置(IETF BCP 47语言标签)默认为
|
|
|
urldecode |
字符串 |
使用特定编码方案解码application/x-www-form-urlencoded字符串。 |
|
|
urlencode |
字符串 |
使用特定编码方案将字符串转换为application/x-www-form-urlencoded格式。有效字符集包括,例如,
|
|
|
user_asset_lookup |
资产丰富化 |
查找单个用户资产。若多个资产匹配输入参数,则仅返回其中一个。 |
|
|
watchlist_add |
监视列表 |
向指定类型的监视列表中添加一个值。成功时返回
|
|
|
watchlist_contains |
监视列表 |
在指定类型的监视列表中查找一个值。成功时返回
|
|
|
watchlist_remove |
监视列表 |
从指定类型的监视列表中移除一个值。成功时返回
|
|
|
周数 |
日期/时间 |
创建一个时间周期,长度为
|
|
|
whois_lookup_ip |
查询 |
检索IP地址的WHOIS信息 |
|
|
years |
日期/时间 |
创建一个时间周期,包含
|
|
示例
|
函数 |
示例 |
|---|---|
|
array_contains |
规则 "array_contains"
当
true
则
set_field("contains_number", array_contains([1, 2, 3, 4, 5], 1));
set_field("does_not_contain_number", array_contains([1, 2, 3, 4, 5], 7));
set_field("contains_string", array_contains(["test", "test2"], "test"));
set_field("contains_string_case_insensitive", array_contains(["test", "test2"], "TEST"));
set_field("contains_string_case_sensitive", array_contains(["test", "test2"], "TEST", true));
结束
|
|
array_remove |
规则 "array_remove"
当
true
则
set_field("remove_number", array_remove([1, 2, 3], 2));
set_field("remove_string", array_remove(["one", "two", "three"], "two"));
set_field("remove_missing", array_remove([1, 2, 3], 4));
set_field("remove_only_one", array_remove([1, 2, 2], 2));
set_field("remove_all", array_remove([1, 2, 2], 2, true));
结束
|
|
concat |
let build_message_0 = concat(to_string($message.protocol), " 连接来自 ");
let build_message_1 = concat(build_message_0, to_string($message.src_ip));
let build_message_2 = concat(build_message_1, " 至 ");
let build_message_3 = concat(build_message_2, to_string($message.dst_ip));
let build_message_4 = concat(build_message_3, " 端口 ");
let build_message_5 = concat(build_message_4, to_string($message.dst_port));
set_field("message", build_message_5);
|
|
contains |
contains(to_string($message.hostname), "example.org", true) |
|
debug |
丢弃来自<source>的消息"let debug_message = concat("丢弃来自 ", to_string($message.source));debug(debug_message);`
|
|
drop_message |
规则 "丢弃超过16383个字符的消息"
当
存在字段("message") 且
正则匹配(模式: "^.{16383,}$", 值: to_string($message.message)).matches == true
那么
drop_message();
// 添加调试信息以通知被丢弃的消息
debug( concat("丢弃过大的消息来自 ", to_string($message.source)));
结束
|
|
ends_with |
返回
ends_with ( "Foobar Baz Quux" , "quux" , true );
返回
ends_with ( "Foobar Baz Quux" , "Baz" ); ` |
|
grok_exists |
当
grok_exists("USERNAME")
那么
let parsed = grok("%{USERNAME:username}", to_string($message.message));
set_field("parsed_username", parsed.username);
结束
|
|
hex_to_decimal_byte_list |
hex_to_decimal_byte_list(值: "0x17B90004"); 返回: [23, 185, 0, 4] hex_to_decimal_byte_list(值: "0x117B90004"); 返回: [1, 23, 185, 0, 4] hex_to_decimal_byte_list(值: "17B90004"); 返回: [23, 185, 0, 4] hex_to_decimal_byte_list(值: "117B90004"); 返回: [1, 23, 185, 0, 4] hex_to_decimal_byte_list(值: "not_hex"); 返回: null |
|
is_not_null |
is_null(src_addr) |
|
lookup |
规则 "目标IP地理信息查询"
当
存在字段("dst_ip")
那么
let geo = lookup("geoip-lookup", to_string($message.dst_ip));
set_field("dst_ip_geolocation", geo["coordinates"]);
set_field("dst_ip_geo_country_code", geo["country"].iso_code);
set_field("dst_ip_geo_country_name", geo["country"].names.en);
set_field("dst_ip_geo_city_name", geo["city"].names.en);
结束
|
|
查找全部 |
规则 "函数查找全部"
当
真
则
令 值 = 查找全部("查找表名", ["键1", "键2", "键3"]);
设置字段("值", 值);
结束
|
|
查找值 |
("IP查找", 转字符串($消息.源地址));
|
|
多模式匹配 |
当
真
则
设置字段(
字段: 多模式匹配(
模式: [
"^ABC %{IP或主机:消息_IP}: %{贪婪数据:ABC消息}",
"^123 %{IP或主机:消息_IP}: %{贪婪数据:123消息}",
"^ABC2 %{IP或主机:ABC_IP}: %{贪婪数据:ABC消息}"
],
值: 转字符串($消息.消息),
仅命名捕获: 真
)
);
结束
|
|
OTX查找域名 |
规则 "解析IP到DNS"
当
有字段("源IP")
&& 正则匹配(
模式: "^\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}$",
值: 转字符串($消息.源IP)
).匹配 == 真
则
令 结果 = 查找值("DNS查找表", 转字符串($消息.源IP));
设置字段("源IP_DNS", 转字符串(结果));
结束
|
|
OTX查找IP |
规则 "解析源IP - OTX-API-IP"
当
// 验证消息有源IP字段
有字段("源IP")
// 验证源IP为IPv4格式
&& 正则匹配(
模式: "^\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}$",
值: 转字符串($消息.源IP)
).匹配 == 真
则
令 结果 = OTX查找IP(转字符串($消息.源IP));
设置字段集(结果);
结束
|
|
解析Unix毫秒时间 |
设置字段("时间戳", 时间戳);
|
|
正则替换 |
令 用户名 = 正则替换(".*用户: (.*)", 转字符串($消息.消息), "$1");
|
|
替换 |
令 新字段 = 替换(转字符串($消息.消息), "oo", "u"); // "fu ruft uta" 令 新字段 = 替换(转字符串($消息.消息), "oo", "u", 1); // "fu rooft oota" |
|
路由到流 |
路由到流(id: "512bad1a535b43bd6f3f5e86"); |
|
以...开头 |
返回真: 以...开头("Foobar Baz Quux", "foo", 真);
返回假: 以...开头("Foobar Baz Quux", "Quux");
|
|
字符串数组添加 |
规则 "字符串数组添加"
当
真
则
设置字段("添加数字到字符串数组_转换", 字符串数组添加(["1", "2"], 3));
设置字段("添加数字数组到字符串数组_转换", 字符串数组添加(["1", "2"], [3, 4]));
设置字段("添加字符串", 字符串数组添加(["一", "二"], "三"));
设置字段("再次添加字符串", 字符串数组添加(["一", "二"], "二"));
设置字段("再次添加字符串_去重", 字符串数组添加(["一", "二"], "二", 真));
设置字段("添加数组到数组", 字符串数组添加(["一", "二"], ["三", "四"]));
结束
|
|
子字符串 |
= 子字符串(转字符串($消息.消息), 0, 20); |
|
转为映射 |
令 JSON = 解析JSON(转字符串($消息.JSON负载)); 令 映射 = 转为映射(JSON); 设置字段集(映射); |
|
流量统计大小 |
set_field(
字段: "license_usage",
值: traffic_accounting_size() // 字节大小
//值: traffic_accounting_size() / 1024 // KB大小
);
|
日志增强
查找表
查找表允许您通过替换消息字段值或创建全新消息字段,来映射、转换或丰富日志数据。例如,您可以使用静态CSV文件将IP地址映射为主机名,或利用外部数据源为消息添加威胁情报、地理位置或资产信息。
该功能能够通过内部系统或第三方集成的上下文增强原始日志数据,将其转化为更丰富、可操作的洞察信息。
组件
查找表系统由四个组件构成:
数据适配器用于实际执行值查找操作。它们可以从CSV文件读取、连接数据库或执行请求以获取查找结果。
数据适配器实现可插拔,新适配器可通过插件添加。
警告
CSV文件适配器会将整个文件内容读入堆内存。请确保相应调整堆内存大小。
缓存负责存储查找结果以提高查找性能和/或避免数据库及API过载。它们是独立实体,使得缓存实现可跨不同数据适配器复用。这样数据适配器无需关注缓存,也无需自行实现。
缓存实现可插拔,新缓存可通过插件添加。
提示
若文件发生变更,CSV文件适配器会在每个检查间隔内刷新内容。如果缓存被清除但检查间隔未到,查找可能返回过期值。
查找表组件将数据适配器实例与缓存实例绑定,用于在转换器、管道函数和装饰器中启用查找表功能。
查找结果由查找表通过数据适配器返回,可包含两种数据类型: 单值 和 多值 .
该 单值 可以是字符串、数字或布尔值,将用于转换器、装饰器和管道规则。在我们通过CSV查找IP地址对应主机名的示例中,这就是主机名字符串。
而
多值
是一种映射或类字典数据结构,可包含多个不同值。当数据适配器能为单个键提供多个值时,此功能尤为实用。例如geo-ip数据适配器不仅提供IP地址的经纬度,还包含该地理位置的城市和国家信息。当前多值功能仅能在使用
lookup()
管道函数时应用于管道规则。
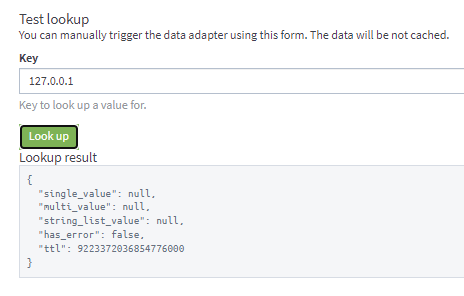
示例1: 包含单值和多值的CSV数据适配器输出示例。
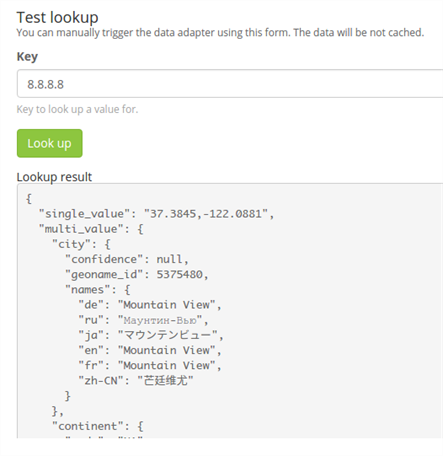
示例2: 包含单值和多值的geo-ip数据适配器输出示例。
配置
您可在 系统 > 查找表 窗口中配置查找表。
每个查找表至少需要一个数据适配器和一个缓存。
-
创建数据适配器:
-
前往 系统 > 查找表 > 数据适配器 .
-
选择 创建适配器 并选择数据适配器类型。
-
填写适配器配置表单(每种类型均附有内置说明文档)。
-
-
创建缓存:
-
转到系统→查找表→缓存。
-
点击创建缓存并选择缓存类型。
-
填写缓存配置表单。查阅表单中包含的缓存特定文档。
注意
除非在配置时选择忽略空结果,否则空结果会被缓存。
-
-
创建查找表:
-
前往 系统 > 查找表 .
-
选择 创建查找表 .
-
选择数据适配器和缓存实例,并可选择定义默认值。
注意
当查找未返回结果时使用默认值。如果在查找表中未找到键, 安全数据湖 会自动返回定义的默认值。
-
创建后,查找表可在提取器、装饰器和管道规则中引用。
用法
查找表可应用于 安全数据湖 的多个领域以丰富数据并赋予上下文:
-
转换器 – 在消息摄取期间对提取值执行查找。
-
装饰器 – 在搜索时丰富消息内容而不修改存储数据。
-
流水线规则 – 通过
lookup()或lookup_value()函数动态应用逻辑。
内置数据适配器
安全数据湖 预置了多种即用型数据适配器。每种类型在 编辑数据适配器 表单中均有屏幕文档说明。
|
适配器 |
描述 |
|---|---|
|
CSV文件适配器 |
从静态CSV文件执行键/值查找。 |
|
DNS查找适配器 |
执行主机名和IP解析(A、AAAA、PTR及TXT记录)。 |
|
DSV文件适配器 |
类似CSV,但支持自定义分隔符和可配置的键/值列。 |
|
HTTPS JSONPath适配器 |
执行GET请求并使用JSONPath表达式提取数据。 |
|
Geo IP – MaxMind |
利用MaxMind数据库提供IP地址的地理定位数据。 |
MongoDB
安全数据湖 新增对MongoDB数据适配器的支持,该适配器将查询数据直接存储于 安全数据湖 配置数据库中。可通过API、图形界面或管道功能添加、更新或删除条目。
通过API管理MongoDB数据适配器
添加键的curl请求示例:
curl -u <令牌>:token \
-H 'X-Requested-By: cli' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-X POST 'http://127.0.0.1:9000/api/plugins/org.graylog.plugins.lookup/lookup/adapters/mongodb/mongodb-data-name' \
--data-binary '{
"键": "myIP",
"值": ["12.34.42.99"],
"数据适配器ID": "5e578606cdda4779dd9f2611"
}'
注意
条目也可直接从 安全数据湖 界面管理,或通过管道规则使用查找相关函数动态修改。
提示
若需在图形界面中为单个键添加多个值,请用换行符分隔每个值。
地理位置
安全数据湖 支持从日志中的IP地址提取并可视化地理位置信息。
本文提供分步指南,说明如何配置地理位置处理器,并利用提取的地理位置数据创建地图。
设置处理器
安全数据湖 默认具备地理位置功能,但 仍需额外配置 。本节详细说明如何配置该功能。
注意
需创建账户以获取许可证密钥来下载MaxMind数据库。更多信息详见 MaxMind博客文章
配置处理器
您需要配置 安全数据湖 以开始使用地理位置数据库解析日志中的IP地址。
-
导航至 系统 > 配置 .
-
选择 插件 > 地理位置处理器 ,然后点击 编辑配置 .
-
勾选 启用地理位置处理器 复选框。
-
从下拉菜单中选择MaxMind或IPInfo。
-
输入您所使用的城市和ASN数据库路径,并可调整刷新间隔。
-
点击 更新配置 以保存设置。
Illuminate与地理位置功能
地理位置配置适用于 Security Data Lake Open版。使用地理位置数据 无需 强制启用Illuminate。
若需在Illuminate内容中获取地理位置数据,必须确保在消息处理器配置中,Illuminate处理器先于GeoIP解析器运行(此顺序应为默认设置)。
检查环境中的配置:
-
前往 系统 > 配置 .
-
选择 消息处理器 ,然后在表格中确认顺序。
如需更改顺序:
-
选择 编辑配置 .
-
按需通过拖放重新排列列表中的项目。
-
选择 更新配置 .
-
强制执行 安全数据湖 架构选项
配置地理位置处理器时,默认会选中 强制执行默认架构 选项。若禁用架构强制,所有非保留IP地址的IP字段都将被处理,并自动添加以下前缀字段:
-
_地理位置 -
_国家代码 -
_城市名称
以
源IP
字段为例,生成的字段可能显示为:
-
源IP_城市名称:维也纳 -
源IP_国家代码:AT -
源IP_地理位置: 48.20849, 16.37208
若启用模式强制,则仅处理以下非保留IP地址的GIM模式字段:
-
目标IP -
目标NAT转换IP -
事件观察者IP -
主机IP -
网络转发IP -
源IP -
源NAT转换IP
以
源IP
字段为例,生成字段可能显示为:
-
源自治系统编号: AS1853 -
源自治系统所属组织: ACONET -
源地理位置城市: 维也纳 -
源地理坐标: 48.20849, 16.37208 -
源地理位置国家ISO代码: AT -
源地理名称: 维也纳, AT -
源地理区域: 维也纳 -
源地理时区: 欧洲/维也纳
在AWS S3中存储地理位置数据库文件
配置页面底部的 从S3存储桶拉取文件 配置页面底部的选项允许您从AWS S3存储桶中拉取地理位置数据库文件。启用此功能后,可在路径配置值中添加S3存储桶URL。
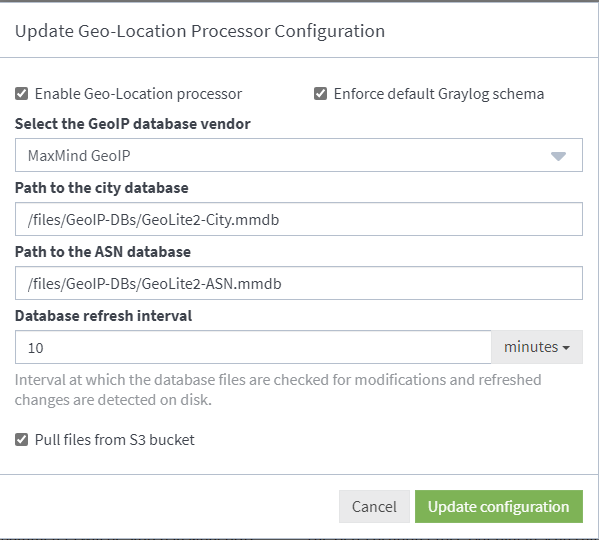
当 启用该功能时 ,系统会按刷新间隔运行服务并轮询提供的S3存储桶中的文件。若文件自上次轮询后有更新,新文件将被拉取至每个节点。该服务依赖 默认凭证提供器 获取S3存储桶的访问凭证,不会使用 安全数据湖 AWS插件配置设置中可能存在的任何配置值。
从S3获取的地理位置数据库文件存储在
安全数据湖
data_dir
目录下的
geolocation
子目录中。要修改文件下载位置,请在
geo_ip_processor_s3_download_location
中设置磁盘目标路径,该参数位于
安全数据湖
服务器配置文件中。
若未启用从S3存储桶拉取文件选项,所有 安全数据湖 节点将从磁盘路径读取文件,且需手动更新这些文件。
在地图中可视化地理位置
安全数据湖
可展示任意字段中存储的地理位置地图,只要地理点采用
纬度,经度
格式。
在搜索结果页面显示地图
在任何搜索结果页面,您可展开搜索侧边栏中需绘制地图的字段。点击左侧边栏的创建按钮(+),从通用菜单中选择聚合功能。
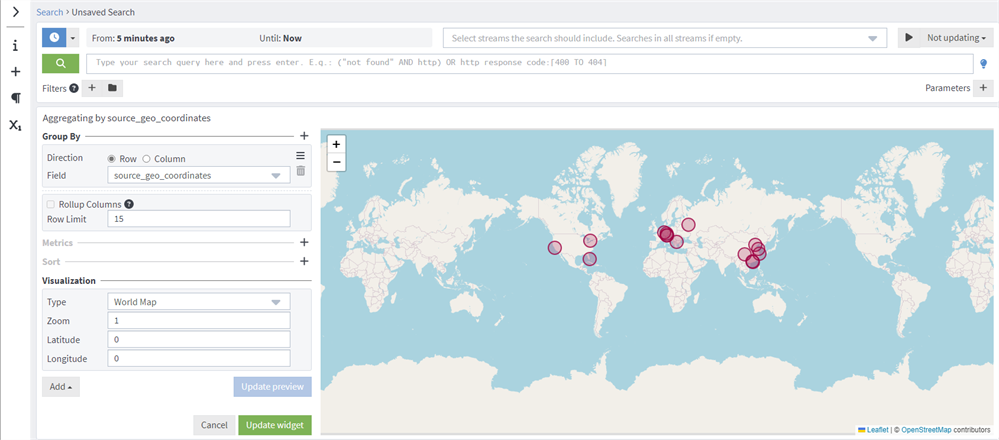
这将生成一个空的聚合组件。点击 编辑 并输入信息,选择世界地图作为可视化类型。随后您将看到该字段中所有不同坐标点构成的地图。
您可以点击 更新预览 查看地图效果,在点击'更新组件'前进行修改。
注意
添加度量指标会影响地图上圆点的大小。若未定义指标,所有圆点半径相同。
关于 安全数据湖 中用于地理坐标源的附加字段,请查阅 安全数据湖 模式文档 .
向仪表板添加地图
您可以像其他组件一样将地图可视化添加到任何仪表板。在搜索结果页面显示地图时:
-
点击右上角三点菜单
-
选择 导出到仪表板 .
随后可对新仪表板进行重命名、编辑和保存。
数据适配器
ThreatFox IOC追踪数据适配器
ThreatFox是 abuse.ch 旗下追踪恶意软件关联入侵指标(IOC)的项目。该适配器支持通过以下关键类型查询:
-
URL
-
域名
-
IP:端口
-
MD5哈希值
-
SHA256哈希值
创建数据适配器时,ThreatFox会下载数据集并存储到MongoDB中。
刷新间隔
配置参数用于确定何时获取新数据集。
示例查询数据
对文件哈希值
923fa80da84e45636a62f779913559a07420a1c6e21f093d87ddfe04bda683c4
进行查询可能产生以下输出:
{
"首次出现时间(UTC)": "2021-07-07T17:03:57.000+0000",
"IOC编号": "158365",
"IOC值": "923fa80da84e45636a62f779913559a07420a1c6e21f093d87ddfe04bda683c4",
"IOC类型": "sha256哈希",
"威胁类型": "有效载荷",
"关联恶意软件": "win.agent_tesla",
"恶意软件别名": [
"AgenTesla",
"AgentTesla",
"Negasteal"
],
"恶意软件显示名": "Agent Tesla",
"置信度": 50,
"参考链接": "https://twitter.com/RedBeardIOCs/status/1412819661419433988",
"标签": [
"agenttesla"
],
"匿名提交": false,
"上报者": "Virus_Deck"
}
配置数据适配器
-
标题-
数据适配器的简短标题。
-
-
描述-
数据适配器的描述信息。
-
-
名称-
数据适配器的唯一名称。
-
-
自定义错误TTL-
错误结果缓存的自定义TTL(可选)。默认值为5秒。
-
-
包含超过90天的IOC-
可选设置,包含超过90天的IOC。默认情况下,数据适配器不包含超过90天的IOC。为避免误报,请谨慎处理超过90天的IOC。
-
-
刷新间隔- 决定获取新数据的频率。最小刷新间隔为3600秒(1小时),因为源数据每小时更新一次。 -
不区分大小写查询- 允许数据适配器执行不区分大小写的查询。
URLhaus恶意软件URL数据适配器
URLhaus是
abuse.ch
旗下的项目,维护用于恶意软件分发的恶意URL数据库。创建数据适配器时,URLhaus会下载相应数据集并存储到MongoDB中。
刷新间隔
配置用于确定何时获取新数据集。
示例查询数据
对URL
https://192.168.100.100:35564/Mozi.m
的查询可能产生以下输出:
{
"single_value": "malware_download",
"multi_value": {
"date_added": "2021-06-22T17:53:07.000+0000",
"url_status": "在线",
"threat_type": "恶意软件下载",
"tags": "elf,Mozi",
"url": "http://192.168.100.100:35564/Mozi.m",
"urlhaus_link": "https://urlhaus.abuse.ch/url/1234567/"
},
"string_list_value": null,
"has_error": false,
"ttl": 9223372036854776000
}
配置数据适配器
-
标题-
数据适配器的简短标题。
-
-
描述-
数据适配器的描述。
-
-
名称-
引用数据适配器的唯一名称。
-
-
自定义错误TTL-
用于缓存错误结果的可选自定义TTL。若未指定值,则默认为5秒。
-
-
URLhaus数据源类型-
决定数据适配器将使用哪个URLhaus数据源。
-
在线URL是较小的数据集,仅包含当前检测为在线的URL。 -
最近添加的URL是较大的数据集,包含过去30天内添加的所有在线和离线URL。
-
-
刷新间隔- 决定获取新数据的频率。最小刷新间隔为300秒(5分钟),因为源数据更新频率即为此。 -
不区分大小写查询- 允许数据适配器执行不区分大小写的查询。